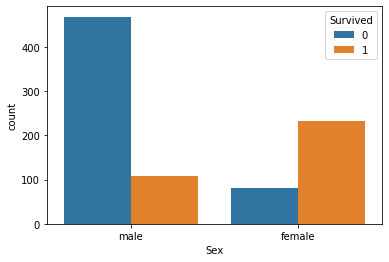시드 고정과 Threshold 설정하는 부분의 코드가 좀 부족해서 점수 재현이 잘 안되지 않을까 걱정되어 잠을 잘 못잤는데, 다행히 잘 봐주신 것 같습니다. 시상식을 갔다 왔는데, "4등에 특별상까지 타고, 정말 축하한다. 설명 문서 제출하는것도 제일 열심히 쓴 것 같고 정말 열심히 논문도 많이 본 것 같고, 관련 전공자도 아닌 뜬금없는 설비, 소방 학과 학생이 이렇게까지 해줘서 놀랐다. 열심히 참가해줘서 고맙다." 라는 엄청난 칭찬을 들었습니다. 몸둘 바를 모르겠습니다. 제가 더 감사합니다...
이번 학기는 학교에서 전공 과목들을 15주(16주) 수업을 12주로 압축하여 수업을 진행하는 3학년 2학기였는데요, 본전공 과목들, 복수전공 과목들, 졸업 필수 교양 과목들이 15주, 12주 수업이 섞여버렸고, 매주 나오는 과제, 팀플 일정과 중간고사 일정이 모두 겹쳐버리는 등의.... 힘든 학기였습니다. 공부하다 힘들어서 코피를 흘린다는게 다 거짓말인 줄 알았는데, 이번 학기 12주 수업이 진행되는 와중에만 코피를 7번을 흘렸네요. (세수하고보니 주르륵. 주르륵. 주르륵.) 그런 와중에 같이 진행하던 대회였어서 정말 힘들었습니다.
하지만 12주 수업을 했던 과목들의 성적도 만족스럽게 나왔고, 큰 대회에서 좋은 성적을 거뒀고, 상을 한개도 아니고 두개! 나 타서 정말 좋습니다. 4위 수상으로 상금을 받고, 특별상으로는 M1 아이패드 프로(11인치) 를 받았는데, 아이패드 8세대를 쓰고 있던 저에게는 정말 만족스러웠습니다. True Tone 최고... ProMotion 최고... M1 짱짱...
데이터는 여러 파일로 나누어져 있지만 크게 보아 총 3개입니다. 학습용, 검증용, 그리고 테스트, 3개입니다. 데이터는 여러 가지의 센서, 액추에이터의 값인데, 이러한 센서값들을 이용해서, 해당 시스템이 공격을 받는지, 이상이 발생하였는지를 맞춰야 하는 문제입니다. 하지만 무턱대고 진행하면 되는 것이 아니고, 학습 데이터에는 '이상 여부' 가 없이 모두 '정상 상태'의 데이터셋만 존재합니다. 정상 상태의 데이터만을 가지고 학습을 진행하여, 시스템의 이상 여부를 판단해야 하는 문제입니다. 아무래도 이상 상태의 데이터는 정상 상태의 센서와 액추에이터 값이 다를 것이므로, AutoEncoder 를 통한 Anomaly Detection 을 진행하는 것 처럼, 데이터의 복원이 잘 안되면 이상 상태인 것으로 간주할 수 있고, 그 기준선을 정하는 것 역시 필요합니다.
다음 중요한 특징은, 시계열 데이터라는 점입니다. 개인적으로 시계열을 매우 어려워하지만, 돌아보니 시계열에 대한 좋은 기억들이 많아 열심히 해봐야겠다 라고 다짐하였습니다. 무작정 표 데이터여서 MLP 를 만들고 시작하면, 시간 순서를 잘 고려하는 것 보다 낮은 성능을 보일 가능성이 매우 높습니다. 실제로 이 데이터로 한 첫번째 실험이 MLP AutoEncoder 였는데, 아주 엉망이었습니다. 그래서 바로 시계열 모델을 만들어야겠다고 생각했습니다.
2. 모델링
최종적으로 사용한 모델은 MLP-Mixer 를 구현하여 사용하였습니다. 구현한 코드는 여기 에 있는 MLP Mixer 구현을 모델 저장하기 편하게, 사용하기 편하게 개인적으로 수정을 하였습니다.
모델은 일단 '시계열'을 바로 다룰 수 있는 모델이어야 하기 때문에, 우선적으로는 RNN, 1D CNN, CNN+RNN, RNN+CNN, Transformer 들의 구조가 생각이 났습니다. Input 으로 time N 까지의 시계열 시퀀스를 받아, N+1 스텝의 센서 값을 예측하는 것이 목표였습니다. 아예 Seq2Seq 구조 처럼 출력 시퀀스를 뱉어내도록 만들어 볼까 하는 생각도 있었지만, 여러 실험을 하면서 코드를 새로 뜯어 고치기는 너무 바빴습니다. ㅠㅠ
첫번째 시도는, Dacon 에서 제공한 Baseline 코드 처럼 Bidirectional RNN 모델입니다. GRU와 LSTM 모두 실험 해 보았는데, 결과는 영 좋지 않았습니다. 검증 데이터셋에서는 아주 낮은 점수를 보였고, 그에 비해서 테스트 셋에서는 상대적으로 높은 점수를 보였습니다. 여기서 검증데이터와 테스트 데이터가 꽤 차이가 있을 수 있겠구나 라고 생각했습니다.
두번째 시도는 CNN을 같이 이용한 모델을 시험해 보았습니다. 1D CNN만을 이용하여 만든 VGG style 의 모델은 전혀 학습을 하지 못했고, RNN과 CNN이 결합된 모델 역시 마찬가지였습니다.
그 다음 시도한 것은 Transformer 모델입니다. Transformer 는 인코더만 만들어서 사용하였습니다. 예측하고자 하는 Timestep이 1개였기에 굳이 디코더까지 만들지 않아도 될 것이라 생각하였습니다. 그렇게 트랜스포머 인코더를 간단히 구현해서 예측을 하였는데, 점수가 눈에 띄게 상승한 것을 확인했습니다. RNN, CNN과 Transformer 가 다른 가장 큰 포인트, '전체 시퀀스를 한번에 볼 수 있느냐' 의 차이가 큰 효과가 있었다고 생각했고, Transformer 모델을 만들기 시작했었습니다. 하지만 Transformer 모델은 입력 시퀀스 길이를 길게 하여 실험을 하다 보니까, 시간이 너무 오래 걸렸고, 제 컴퓨터로 하기에는 답답해졌습니다.
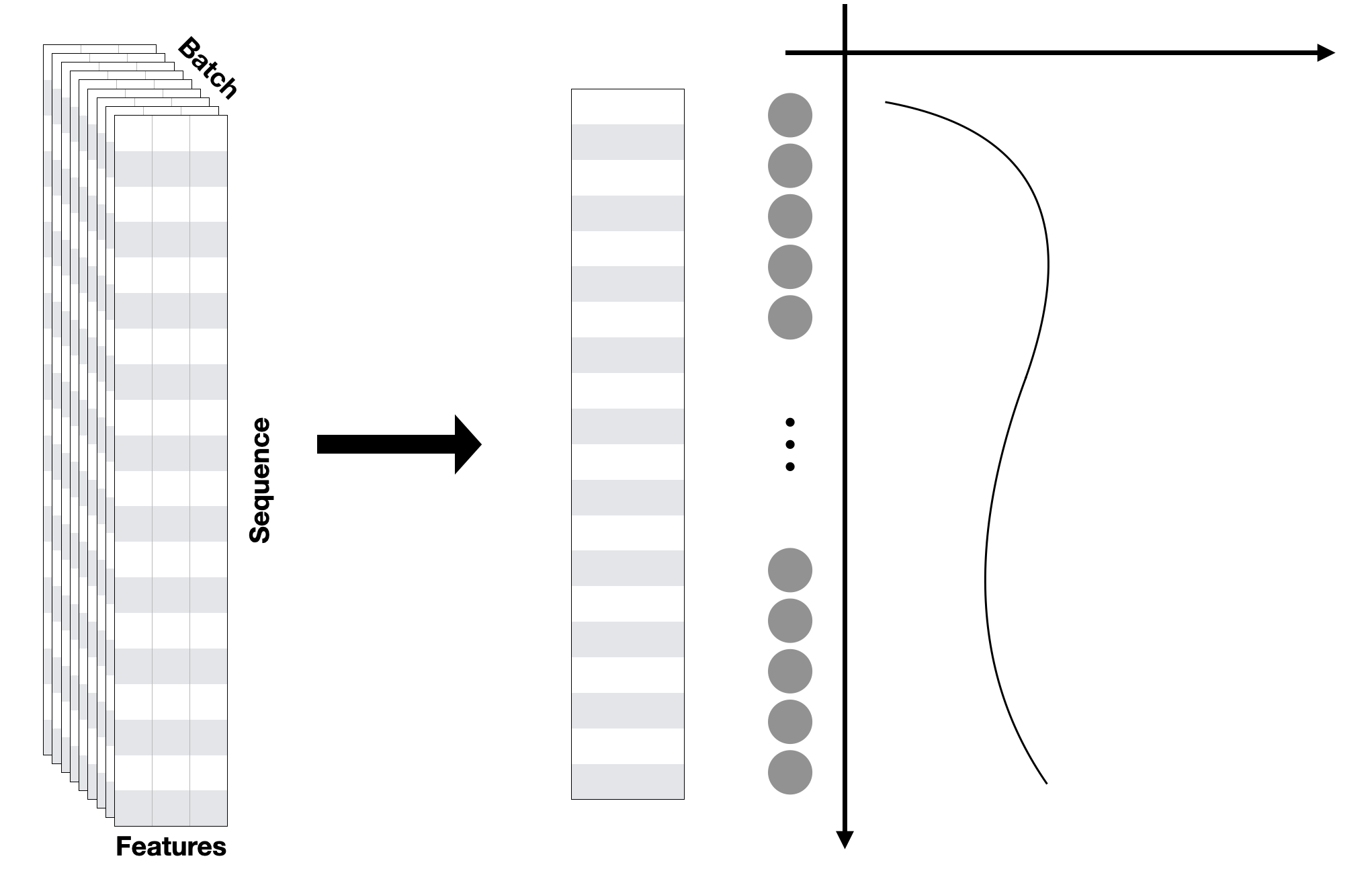
그래서 최종 결정한 모델이 MLP-Mixer 입니다. MLP Mixer 는 Transformer 처럼 한번에 전체 시퀀스를 다룰 수 있지만, 더 가볍고, 빠르고, VRAM이 모자란 제 컴퓨터에서 더 잘 돌아갈 것 같았고, MultiHeadAttention 과정보다 'Function Approximator' 에 가깝다고 볼 수 있다고 생각했습니다. 이러한 시계열 문제에서 Self Attention이 작동하는 과정은 (수학적으로 정확한 설명은 아니지만), Sequence 내의 각 Timestep간의 연관성, 중요도를 계산하는 것이라 생각했습니다. 하지만 MLP Mixer 는 각 Timestep 간의 연관성, 혹은 중요도, 관계를 파악하는 것이 아니라 함수로 표현하는 것이라 생각해서, 이것도 충분히 가능성 있는 모델이라고 생각했습니다. 제가 이해하고 있는 두 모델의 차이를 키노트로 그려 보았는데, 아래 그림과 같습니다.
Sequence in Self Attention
Sequence in Mixer
하지만 MLP-Mixer 를 구현하여 학습을 진행해보니, 너무 빠르게 Overfit 되는 현상이 있었습니다. 그래서 MLP Mixer 에다가 Sharpenss Aware Minimization 을 추가해서 학습하기로 생각했습니다. 이 논문(When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations) 에서 보면, ViT와 Mixer 의 학습을 SAM 을 이용해서 도울 수 있다고 나와있습니다. 그래서 Mixer 와 SAM을 같이 써서 Overfitting 을 줄이고, Transformer + SAM 모델보다 더 빠르게 많은 모델을 만들어서 결과물을 앙상블 하는 것이 더 효율적으로 좋은 결과를 낼 것이라 생각하였습니다. 하지만 가장 큰 이유는, MLP-Mixer 논문 마지막 부분에, '다른 도메인에서도 잘 먹히는지 봐도 좋을 것 같다' 고 쓰여있어서 시도해본 것이 결정적 이유였습니다.
MLP-Mixer 를 구현하고 나서, 어느 정도 성능이 잘 나오는 것을 확인하였습니다. 1D CNN, RNN보다 Transformer 와 Mixer 의 성능이 높게 나오는 것을 보아, 전체 Sequence 를 한번에 보고 처리하는 모델이 더 잘 작동하고 있고, 두 모델 모두 컴퓨터에서 돌아가는 선에서는 성능이 유사하게 나온다면, 복잡한 모델보다 단순한 모델이 낫다는 생각으로 MLP-Mixer 를 여러 타임스텝에 맞춰 Scale Up, Scale Down 한 16개의 모델을 만들고, 그 앙상블 모델을 최종 모델로 선택했습니다. MLP AutoEncoder 를 만들 때, 무작정 층 수를 늘리거나 뉴런 수를 많게 한다고 반드시 좋은 모델이 되지 않는다는 생각과 맥락을 같이 합니다.
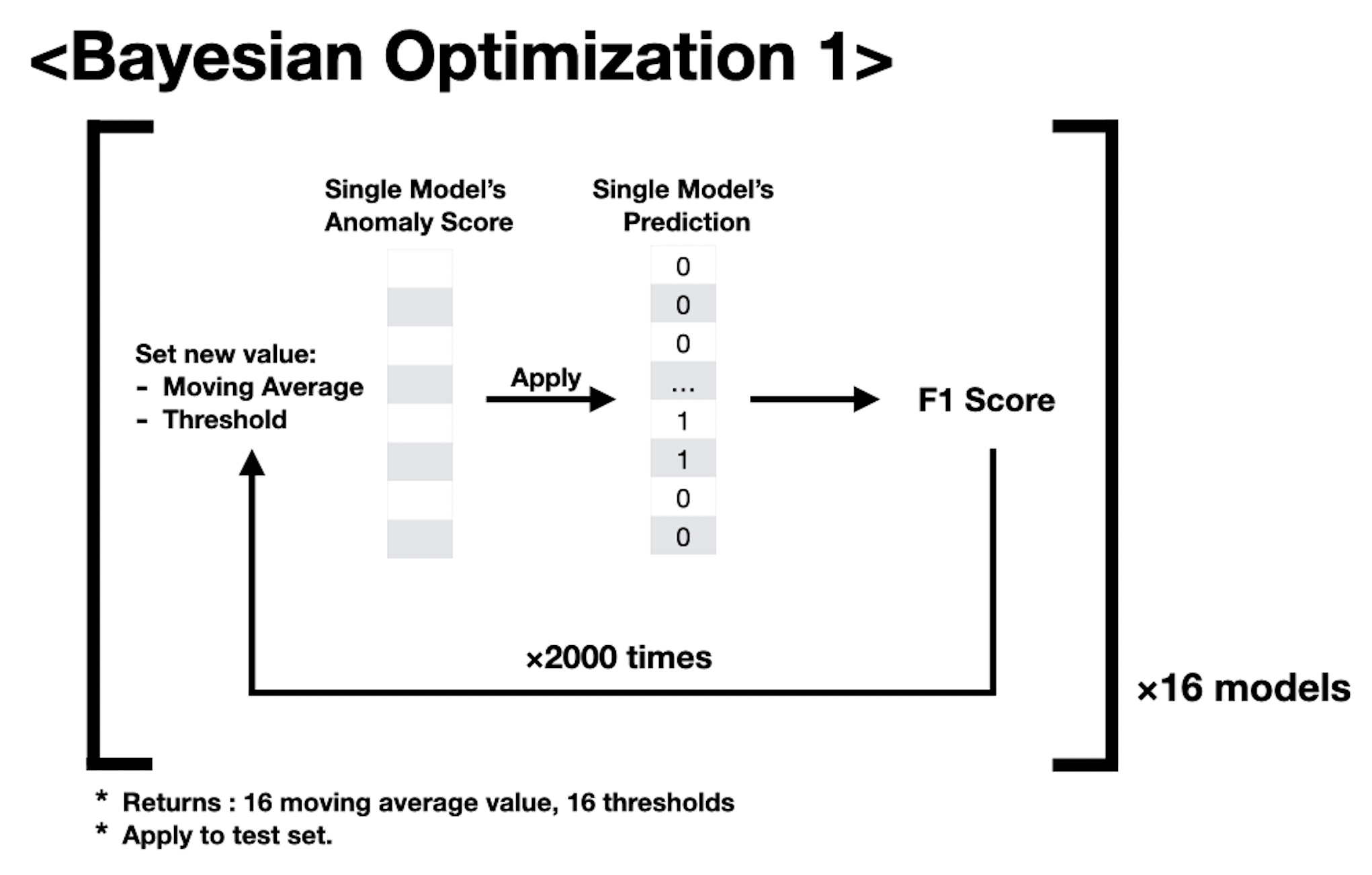
모델만큼 성능에 중요한 영향을 끼친 부분은 Threshold 를 정하는 일이었습니다. Threshold 는 optuna 를 사용하여 2000회의 반복을 통해서 결정하였습니다. 무작정 RandomSearch 를 하는 것 보다는 Bayesian Optimization 을 하는 것이 좋다고 판단했고, 평소 하이퍼파라미터 튜닝에 optuna 를 많이 사용해서 익숙한 함수를 만들듯이 적용할 수 있었습니다. 먼저 16개 예측값에 대하여, 이동 평균을 이용해 예측 결과물을 smoothing 시키고, threshold 를 결정해 [0, 1, 0, 0, ...] 과 같은 예측 결과물을 만들었습니다. 적용할 이동평균 값과 threshold 를 아래 그림과 같이 반복을 통하여 구했습니다.
Decide MA, Threshold
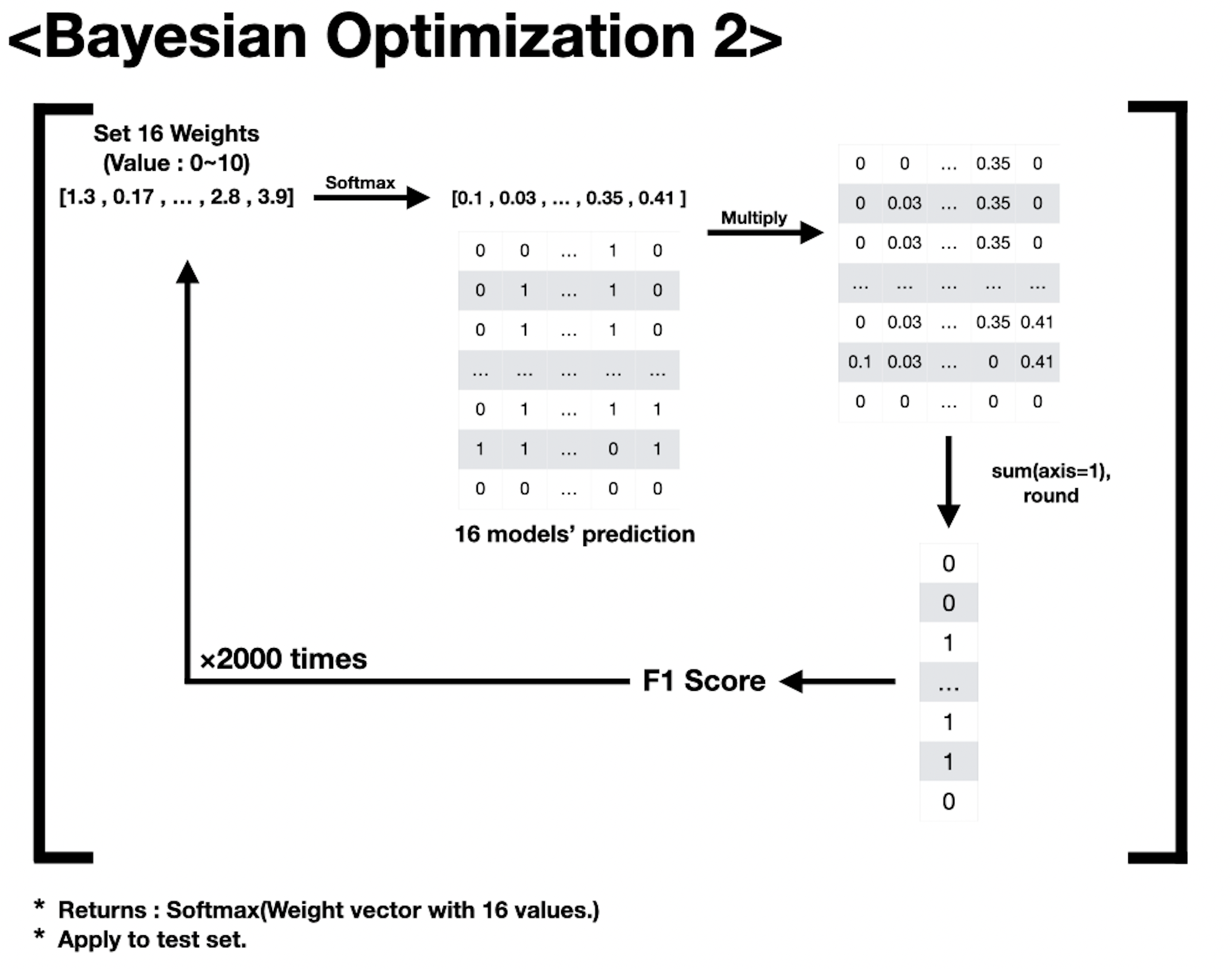
다음으로는 16개 예측 결과를 조합하는 과정 역시 optuna 를 이용해서 만들었습니다. 0과 1로 이루어진 예측 결과물들을 softmax 함수를 거친 weight vector 를 통해 Soft Voting 하도록 하였습니다.
Soft Voting Ensemble of 16 predictions
이러한 파이프라인을 만들었는데, 이 과정에서 가장 큰 문제는 검증 데이터에 대한 Overfitting 이 매우 잘 일어난다는 점이었습니다. 2020년 대회에 적용했을 때는, 먼저 예측값을 만들고 Voting 하는 것이 그닥 좋은 결과를 내지 못했는데, 2021년 대회에는 잘 적용되는 것을 확인했습니다. 제가 내년 대회에도 참여하게 될지는 잘 모르겠는데, 이 부분은 실험을 통해서 대회마다 다르게 적용되어야 할 것 같습니다.
3. 결론, 느낀점
검증데이터셋의 활용이 정말 힘들었던 대회였습니다. 학습에는 절대 사용하면 안되지만, Early Stopping 을 걸거나, 검증 데이터셋 일부를 학습 데이터셋에 포함시켜서 Scaling 하는 것은 허용되었고, 검증 데이터셋 점수와 테스트 데이터 점수가 일관성이 별로 없게 나와서 혼란이 많았던 대회라고 생각합니다.
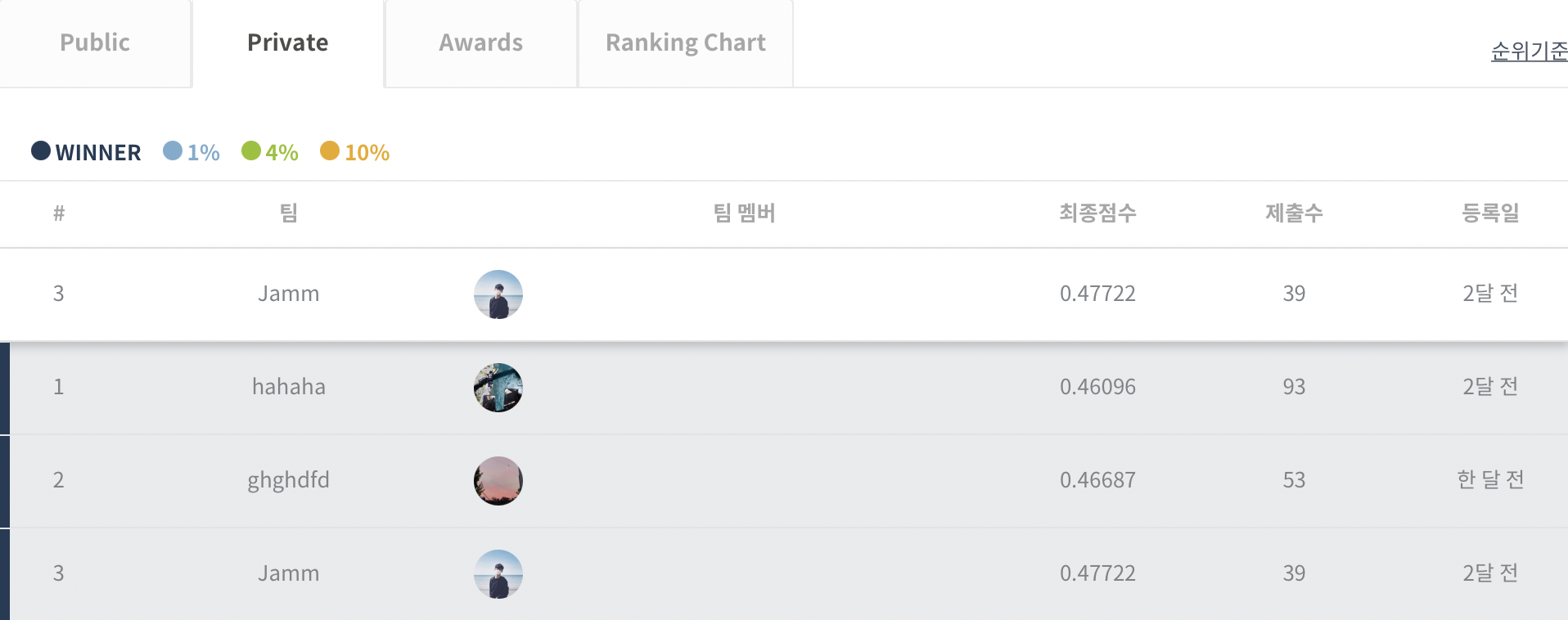
2020년에도 HAICon이 진행되었는데, 1년 전에 저는 이 과정을 이해를 못하고, 1D CNN으로 만든 모델 3번 만들어보고, 대회가 이해가 되지 않아 포기했었던 기억이 납니다. 비슷한 시기에 올해도 비슷한 대회가 진행되어서, 1년 사이에 제가 조금은 성장했구나 라는 생각이 들어서 기뻤고, 좋은 결과까지 얻어서 더욱 기쁩니다. Public LB에서 7위였기 때문에 3등 안으로 들어가는 것은 상상도 하지 못했었고, Private LB도 뚜껑을 열어 보니 3등팀과의 점수 차이는 어마어마해서, 4등에 매우 만족하고있습니다. 더 열심히, 정진하도록 하겠습니다.
2020년은 개인적으로 최고의 상승장이었지만, 2021년에는 다시 하락장이 시작되고있네요. 하락장 와중에 있었던 반등 같은 대회였습니다.
월간 데이콘 13으로 진행되었던 운동 동작 분류 AI 경진대회에서 최종 3위를 기록하게 되었습니다. 무야호~
그만큼 신나시다는 거지!
전체 파이프라인 코드는 깃헙과 데이콘 코드공유 (맨 위의 링크 두개)에 올려져 있으니, 코드 자체를 블로그에 다시 적는건 의미가 없을 것 같고, 대회 중에 들었던 생각들과 과정들만 정리해보도록 하겠습니다.
1. 데이터
총 600개의 timestep 을 가진 시계열 센서 데이터가 주어졌습니다. 해당 센서는 오른쪽 팔에 자이로스코프, 가속도계가 달린 센서를 착용하고, 특정 운동 동작을 수행했을 때, 그 동작이 61개 동작 중에서 어떤 class 에 해당하는지를 맞추는 Classification 문제였습니다. 데이터는 csv 파일로 주어지지만, 시계열 데이터에 맞춰 numpy array 로 reshape 하면 총 3125개의 센서 값이 기록되어 있음을 알 수 있습니다. 데이터가 아주 많지는 않네요. (Original Shape : (3125, 600, 6))
때마침 애플워치를 구입한지 얼마 되지 않았던 시기였기 때문에, 워치를 생각하며 애플워치를 착용하고 운동을 하는구나 라고 생각하고 대회에 재밌게 참여할 수 있었습니다.
1.1. 라벨 불균형
대회 초반에 모델을 무작정 만들고 있을때도 어느 정도의 점수는 나왔었지만, 특정 점수 이상으로 잘 올라가지 않는 느낌을 받았습니다. 그래서 혹시나 해서 타겟변수를 살펴보니
총 학습데이터 3125개 중 절반이 26번, 나머지 절반 데이터를 60개 동작이 나눠먹고 있는 모습
상당히 imbalance 가 심한 것을 확인했습니다. 3000여 개의 데이터중에서 한 클래스의 갯수가 12개라니... 이거 너무한거 아니냐고? 응아니야
점수를 더 올리려면 이걸 해결해야겠다고 생각했습니다.
1.2. Feature Engineering
feature_names = ['acc_x','acc_y','acc_z','gy_x','gy_y','gy_z']
grad_cols=[]
for col in feature_names:
grad_cols.append(f"grad_{col}")
integ_cols = []
for col in feature_names:
integ_cols.append(f"integ_{col}")
#position_cols = ['pos_x','pos_y','pos_z']
total_feature_names = feature_names + grad_cols + integ_cols #+ position_cols
고등학교때 수학시간에 들었던 말이 생각났습니다. 미적분 문제에 접근하는 것을 유독 힘들어했었는데, 선생님께서 '일단 속도가 보인다? 미분 할 생각부터 해라. 가속도를 구해야 풀리는 문제들이다' 이런 뉘앙스의 말을 하셨습니다. 주어진 데이터는 가속도 x, y, z 와 각속도 x, y, z 이므로 이들을 미분해서 가가속도, 각가속도를 만들고, 적분도 해서 속도, 각도 변수도 만들었습니다. 이렇게 적분했던 속도를 한번 더 적분하여 변위를 만들어서 사용했었는데, 이렇게 연속으로 적분을 하니까 오차가 점점 누적되어서 그런가, 의미가 없는 결과값을 얻었습니다.
예전에 캐글의 Ion Switching 대회에서도 이렇게 gradient 를 만들어서 접근을 했던게 생각났습니다. 그때는 lag feature, delta features, moving average features 역시 만들어서 추가했었는데, 대회 중에는 생각이 안나서 시도해보지 못했던 것이 아쉽습니다.
이렇게 해서 사용한 변수는 총 6 * 3 = 18개의 변수를 사용하였습니다.
2. 모델
2.1. Augmentation
이번 대회에서 가장 아쉬움이 남았던 부분입니다. 1위 솔루션을 보았는데 정말 여러가지 Augmentation 기법들을 시도하고 사용해 보셨더라고요. 심지어 라벨에서 'left arm', 'right arm' 이라고 쓰여진 부분도 있었는데, 전부 다 오른팔에 착용했다고 생각하고 다른 augmentation 을 생각조차 하지 않았다는 점이 좀 아쉬웠습니다.
처음에는 도저히 감이 잡히지 않았지만, Dobby님 께서 올려주신 코드 공유를 보고, 이런 방식으로 접근하면 되겠다고 생각했습니다.
numpy의 roll 을 이용하여 augmentation을 하면, 머릿속으로 동영상을 만들어 봤을 때 해당 센서 데이터가 Loop 처럼 반복된다고 볼 수 있다고 생각이 들었습니다. 킹도비 아이디어 갓... 직접적으로 저 코드처럼 구현을 하지는 않았지만, tf.roll 을 사용하여 커스텀 레이어를 만들어서, 학습시에는 랜덤한 값으로 Augmentation 을 수행하고, test 시에는 적용되지 않도록 구현하였습니다.
# 모델의 인풋 바로 다음에 랜덤한 값으로 Rolling 을 하는 커스텀 레이어.
class Rolling(Layer):
def __init__(self, roll_max=599, roll_min=0):
super(Rolling, self).__init__()
self.random_roll = random.randint(roll_min, roll_max)
#def build(self, input_shape): # Create the state of the layer (weights)
# pass
def call(self, inputs, training=None):# Defines the computation from inputs to outputs
if training:
return tf.roll(inputs, shift=self.random_roll, axis=1)
else:
return inputs
def get_config(self):
return {'random_roll': self.random_roll}
2.2. Minority Oversampling
# 데이터를 하나하나마다 다른 Rolling 과 다른 노이즈를 추가하여 오버샘플링 하는 용도의 함수
def aug_data(w, noise=True, roll_max=550, roll_min=50, noise_std=0.02):
assert w.ndim == 3
auged=[]
for i in range(w.shape[0]):
roll_amount = np.random.randint(roll_min, roll_max)
data = np.roll(w[i:i+1], shift=roll_amount, axis=1)
if noise:
gaussian_noise = np.random.normal(0, noise_std, data.shape)
data += gaussian_noise
auged.append(data)
auged = np.concatenate(auged)
return auged
위에서 확인했듯, Imbalance 가 매우 심합니다. 3125개중에 12개를 정확히 맞추는 것은 아무리 생각해 보아도 선을 넘은 것 같습니다. 그래서 Oversampling을 해 주었습니다.
학습을 Stratified 10 Fold CV 를 하였는데, 매 Fold 마다 train과 valid를 쪼갠 이후, train데이터의 26번(Non-Exercise)항목이 아닌 데이터들만 뽑아서 위 함수를 이용하여 적용시켜 주었습니다. 원본 데이터를 그대로 복사하는것은 아니고, 데이터 전체가 아니라 각각의 데이터마다 랜덤하게 roll을 해주고, 약간의 가우시안 노이즈를 추가하여 train 데이터에 concat 하였습니다. 1번 정도만 적용하니 성능이 향상되었고, 2번 이상부터는 overfit이 쉽게 일어나는 것 같았습니다.
2.3. Modeling
모델 구조는 여러 가지를 생각해 보았는데,
Conv1D 이후 Dense (VGG-like)
RNN (LSTM / GRU) 이후 Dense (Stacked LSTM)
RNN 과 Conv1D 를 섞어서 Skip Connection을 골고루 넣는 (떡칠하는) 모델
RNN Path 와 Conv1D Path 를 따로 두고 Concat하여 Timestep 과 Local feature들을 동시에 고려하는 모델
들이 생각이 났었는데, 최종 모델로 선택한 것은 1번 이었습니다. 레이어를 아무리 넣고 빼고 자시고를 반복해도 RNN계열 층이 섞여있을 때는 성능이 생각보다 잘 나오지 않았습니다. 개인적으로 시계열 문제를 굉장히 싫어하는데, (잘하고싶은데, 잘 안돼요..) 아직까지는 한번도 RNN 계열 층을 써서 CNN보다 잘 나오는 경우를 못겪어봤습니다...
# Convolution, Dense 레이어 여러번 적기 번거로워서 만든 함수
def ConvBlock3(w, kernel_size, filter_size, activation):
x_res = Conv1D(filter_size, kernel_size, kernel_initializer='he_uniform', padding='same')(w)
x = BatchNormalization()(x_res)
x = Activation(activation)(x)
x = Conv1D(filter_size, kernel_size, kernel_initializer='he_uniform', padding='same')(x)
x = BatchNormalization()(x)
x = Activation(activation)(x)
x = Conv1D(filter_size, kernel_size, kernel_initializer='he_uniform', padding='same')(x)
x = Add()([x, x_res])
x = BatchNormalization()(x)
x = Activation(activation)(x)
return x
def DenseBNAct(w, dense_units, activation):
x = Dense(dense_units, kernel_initializer='he_uniform')(w)
x = BatchNormalization()(x)
x = Activation(activation)(x)
return x
def build_fn(lr = 0.001):
activation='elu'
kernel_size=9
model_in = Input(shape=Xtrain_scaled.shape[1:])
x = Rolling(roll_max=599, roll_min=0)(model_in)
x = SpatialDropout1D(0.1)(x)
x = ConvBlock3(x, kernel_size=kernel_size, filter_size=128, activation=activation)
x = MaxPooling1D(3)(x)
x = SpatialDropout1D(0.1)(x)
x = ConvBlock3(x, kernel_size=kernel_size, filter_size=128, activation=activation)
x = GlobalAveragePooling1D()(x)
x = DenseBNAct(x, dense_units=64, activation=activation)
x = Dropout(0.4)(x)
model_out = Dense(units=61, activation='softmax')(x)
model = Model(model_in, model_out)
model.compile(loss='sparse_categorical_crossentropy', optimizer=Nadam(learning_rate=lr), metrics='accuracy')
return model
build_fn().summary()
VGG 스타일의 심플한 Conv1D 모델입니다. Conv1D는 커널사이즈를 꽤나 크게 잡아도 파라미터 수가 엄청 뻥튀기 되지 않고, 오히려 충분한 커널사이즈가 있어야 Timeseries 의 컨텍스트를 잡아낼 수 있을거라 생각해서 커널 사이즈를 흔히 Conv2D에서 사용하는 3이 아니라 9로 정했습니다.
이후 학습은 Stratified 10Fold CV를 사용하여 10개 모델의 평균을 내어 제출하였습니다.
3. 기타 다른 아이디어
캐글의 ion switching 대회에서 나왔던 Kalman Filter 를 이용한 noise smoothing - 데이터가 상당히 깔끔하게 잘 나와있었어서 굳이 할 필요가 없었다고 생각이 듭니다.
데이터들의 statistics 들을 통한 aggregation, 및 Tree 기반 모델 접근 - 대회 초반에 가만히 생각해 보았지만, '굳이 데이터를 요약?까지 해야 하나? Conv1D나 LSTM, GRU 쓰면 바로도 충분히 접근할 수 있을 것 같은데.' 라는 생각에 시도해보지는 않았습니다.
Stacking(meta-modeling) - 스태킹을 할때 test 셋을 bagging 해서 만들면 oof로 만들어진 meta training set과 bagging으로 만들어진 meta test set이 차이가 나서 그런가, 점수가 잘 오르지 않는 모습을 예전부터 보고 있었습니다. 스태킹 잘하시는 분들 혹시 이 글을 보신다면... 꿀팁 알려주시면 감사하겠습니다. 개인적으로 앞으로도 평균 앙상블은 정말 많이 사용할 것 같은데, 스태킹은 거의 안하게 될 것 같습니다. 좀 많이 양보하면.. 단순평균 아니라 가중평균정도...?
4. 결론 및 아쉬운 점
다른 대회에서도 저는 Augmentation을 잘 안하는 편인데, 역시나 이번에도 마찬가지였습니다. 항상 적절한 augmentation 방법을 찾아 적용하는데 실패해서 매번 버리는 경우가 많았는데, 이 대회에서는 Augmentation 에 더 노력을 덜 기울였던 점이 끝나고 보니까 아쉬움으로 남는 것 같습니다. 충분한 Augmentation으로 성능이 잘 나오는 데이터였는데, 위에 생각했던 것들을 하나씩 하고 나니까 리더보드 수상권으로 들어오기도 했고, 너무 안일하게 슬슬 마무리 짓자 라는 생각을 했던 것 같습니다. 기회가 된다면 다른 유저분들이 사용했던 Augmentation 방법론들을 또 추가해보고, (특히 왼손 오른손 Augmentation이 제일 인상깊었습니다...) 한번 더 해보고 싶은 대회네요. 데이터도 작아서 데스크탑 정도로 부담 없이 재밌게 진행할 수 있었고, CV-LB 점수가 상당히 정직하게 나와서 접근하기 좋았던 대회였던 것 같습니다.
기말고사가 드디어 끝났습니다. 얼마 전 시험 시작 전에 한국수력원자력에서 진행했던 데이콘 대회의 최종 순위가 발표되었고, 정말 운이 좋게도 우승이라는 좋은 결과를 얻을 수 있었습니다. 개인적으로는 친구들이 양주사라, 코로나만 잠잠해지면 회식 가자 하는 중이고.. 양가 친척 모두에게 소문이 나서 '아이고 장하다 고놈' 그런 이야기를 듣고 있었습니다. 신문 기사에서 너무 대문짝만하게 나오기도 해서 너무 부끄럽고, 학교 홈페이지에도 올라가서 수업듣는 교수님이 '너가 그 우승한 걔 맞냐' 물어보시기도 했습니다... 아싸는 부담스러워요...
지금까지 공부하면서 얻었던 가장 좋은 성적이었기에 얼른 공유를 하고 싶었는데, 코드의 저작권과 데이콘과 작성했던 양수양도 계약서, 상금 지급 여부 등의 문제 때문에 바로 올리지는 못하고 약간 뒷북이 되긴 하였지만 이제서야 올릴 수 있게 되었습니다. 개인적으로 너무 힘들었던 대회였고, 마지막까지 예측이 안되던 대회였어서 얼떨떨하고 합니다...
사실 코드를 안올리는 진짜 이유는...코드 내에 오타가 있었어서...아래에 썼던 '생각했던 모델' 과 연결구조가 약간 다릅니다... 층을 3개 쓰려고 했는데 두개만 들어갔다던가... 이걸 대회 끝날때까지 모르고 있다가, 코드 제출하면서 찾았다니 어이가 없을 뿐입니다...
1. 데이터 소개
데이터셋에 대해서 이야기를 하자면, 학습데이터로는 (120, 120) 의 레이더 사진이 4장, 타겟 데이터로는 (120, 120)의 한장이 주어졌습니다. 샘플의 수는 약 6만여개가 주어졌고, npy 파일로 데이터를 받을 수 있습니다. 4장의 사진은 (30분 전, 20분 전, 10분 전, 현재) 의 4장의 사진을 가지고 10분 후의 사진 1장을 예측하는것이 목표입니다. 이렇게 레이더 사진을 예측하여 제출하면 레이더 사진을 강수량으로 변환하여, 강수 여부(정확도, 정확히는 CSI)와 강수량(MAE) 를 계산하여 점수를 얻게 됩니다.
이미지의 시계열 데이터라고 생각을 했습니다. '이미지의 시계열이면 동영상 아니야?' 하는 생각에, 대회 초반에는 케라스의 ConvLSTM2D 층을 잔뜩 쌓은 모델을 만들려고 했습니다. 또 어떻게 보면 구름이 있어야만 비가 올 수 있으니, 미래 이미지에 대한 Segmentation으로도 접근할 수 있겠다고 생각하고 있었습니다. (CSI만 생각하면 어느정도 비슷한 접근이라고 생각합니다.) 하지만 ConvLSTM2D의 결과는 점수상으로 엉망이었고, 아 이게 아닌가 어떻게 하지 하며 고민하는 와중에 데이콘에서 Baseline 코드가 올라왔고, UNet이라는 것을 알게 되었습니다.
RainNet의 구조 역시 UNet과 거의 같았습니다. 깃헙 안에 있는 모델 코드를 보면 두군데 Dropout이 추가되었습니다. 이 RainNet에 따르면 데이터는 레이더 영상이 아니라 강수량으로 변환한 데이터였고, Loss Function은 LogCosh라고 검색을 하다가 봤던 것 같습니다. 아무튼 이 UNet Style Model이 효과가 있다는 것은 확인했습니다.
2. 모델링
최종적으로 작성한 모델링 아이디어
키노트로 모델 구조를 그려보았습니다. 기본적인 UNet 구조로 흘러가는 Path 1 과, ConvLSTM2D를 거치는 Path 2 가 있고, 마지막에는 둘을 합쳐 마지막 Convolution을 진행하여 출력하고, 출력 Convolution을 3 * 3 으로 두었습니다. 이렇게 하면 구름의 주변 값도 고려하지 않을까 라고 생각했는데, 1 * 1 Convolution 과의 비교를 할 시간이 없었어가지고, 약간 아쉽습니다. Upsampling 층 대신에 Conv2DTranspose를 사용했고, RainNet에 있던 Dropout 위치에다가 그림에는 지금 Dropout 이라고 표시되어 있지만 SpatialDropout2D를 사용했고, 활성화함수는 ELU를 사용했습니다. 개인적으로 mish 를 정말 좋아하는데 이번에는 mish를 못써서 속상했습니다(?) 왜 좋냐고요? 그냥 이름이 이뻐서...
그림에는 그냥 나와있지만, 필터수 256, 512에서는 제가 '월간데이콘 6, 음성 중첩 분류 대회' 에서 사용했던 선형 Bottleneck 구조를 다시 사용했고,(파라미터 수를 줄이고 오래 걸리는 모델을 얻었다...) 모든 3번의 Convolution 블럭? 의 첫번째와 세번째를 잇는 Additive Skip Connection이 들어있습니다. 개인적으로 스킵커넥션이 Add 인 경우는 뭔가 '야 이게 맞으니까 당장 반영해.' 느낌이 있고, Concat인 경우는, '자 이렇게 될 수도 있는데 같이 생각해봐~' 이런 느낌이었습니다.
그냥 UNet만 사용하다가 ConvLSTM2D를 추가하게 된 이유는 다음과 같습니다.
Conv 층의 필터끼리는 Dense Layer 와 비슷하게 연산된다. -> 이렇게 되면 시계열 순서가 담고있던 의미가 섞이게 될 것입니다.
(예전에 어떤 블로그에서 읽었던 글인데, 기억이 안나요 죄송합니다.) 신경망은 Sparse 할 수록 성능이 좋다, 인셉션이 성능이 좋았던 이유. 라고 설명을 해 주셨었는데, 지금도 Sparse가 어떤 의미인지 완벽히 이해하지 못하고 있지만, 인셉션 구조의 컨셉? 그림? 이 생각이 나서 이런식의 디자인이 나름의 인셉션 역할을 하지 않을까 라고 생각했습니다.
ConvLSTM2D층 한개짜리 모델의 결과를 시각화 해 보았더니, 생각보다 성능이 좋아 보였다. -> 아주 개인적으로는 구름이 대충 '어디에 있는지' 정도는 층 하나로도 잘 잡아내는 듯 했습니다. 하지만 구름 모양의 세부적인 모양 디테일이나 그 값을 잘 잡아내지 못했기 때문에 점수가 잘 나오지 않았다고 생각했습니다. 그래서 ConvLSTM 구조로 모양을 잡고, UNet 구조로 디테일을 잡아서 합치면 어떨까? 하는 생각에 이렇게 만들게 되었습니다.
학습, 예측 과정은 특별한 과정 없이 10 Fold Cross Validation을 하였고, Early Stopping을 걸어서 Fold 별로 베스트 모델을 저장해두었다가, 10개 모델들의 결과물의 단순평균을 구해서 제출했습니다. 오랫동안 1등을 유지하고있었던 0.50033(?) 점의 모델도 이 구조의 단일 모델 결과였습니다. 그래서 평균 앙상블 모델의 Public 점수는 매우 별로였지만 그래도 선택 할 수 있었다고 생각합니다.
3. 기타 시도했던 것들 / 대충 시도 또는 생각만 해본....
Metric 을 AUC 로 둔 것. 픽셀별로 0~1 값이니까 뭔가 측정이 될 수 있지 않을까 하는데 의미 없었습니다.
Grouped Conv2D. Timestep이 4니까 UNet의 Conv에서 group을 4로 주고 해보았습니다. 지금 봐도 나쁘지 않은 생각인 것 같은데, 할 수 있다면 다시 해보고 싶습니다.
TimeDistributed(Conv2D). 이거 할 바에는 그냥 ConvLSTM2D를 해야겠다 생각했습니다.
UNet Style ConvLSTM2D. ConvLSTM을 64로 시작해서, UNet의 모든 Conv 층을 ConvLSTM으로 대신할 수 있을까 생각했지만 컴퓨터가 못버텨서 빠른 포기.
Input -> ConvLSTM2D -> UNet 구조 / UNet에서 가운데 층만 ConvLSTM2D. 전자의 경우는 좀 더 생각해볼 수 있지 않을까 싶은데, 후자의 경우는 Conv2D 통과하는 순간 시계열이 섞이기 때문에 틀린 생각이었다고 생각되네요. 시간 압박때문에 ConvLSTM2D 층을 두개 이상 쓰기는 정말 힘들었습니다.
Input -> DownSample -> ConvLSTM2D -> Upsample. 모델 크기는 작아지긴했지만, 대책없이 DownSampling을 해서 그런가 정보 손실이 있을 것 같습니다.
DownSampling 시에 CBAM 어텐션, UpSampling 시에는 'Attention UNet' 의 Attention Gate 추가. 둘다 썼을 때나, 둘중에 하나만 썼을 때나 둘다 결과가 그닥 좋지 않았습니다. 논문에 있는 그림 보고 무작정 만들어 봤었는데, 잘못 만들었을 것 같은 느낌이 확 드네요. 이것도 다시 해보고 싶은 아이디어 입니다.
4. 결론
정말 너무 힘든 대회였습니다. 제출할 때마다 Public LB 점수는 오락가락 하고 있고, 모델 하나 만들어서 제출하는 시간은 너무 오래 걸리고, 컴퓨터는 이러다가 불날 것 같았고... 하지만 운이 잘 따라주었다고 생각합니다. 저는 여전히 부족한게 너무 많네요... 아직은 실력에 비해서 Over Prized(?) 된 것 같습니다. 그래도 상은 감사히 받고, 상값은 앞으로 더 열심히 해서 갚도록 하겠습니다.
import os
import pandas as pd
import numpy as np
import scipy
from tqdm import tqdm
from glob import glob
from scipy.io import wavfile
import librosa
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import time
sns.set_style('whitegrid')
import warnings ; warnings.filterwarnings('ignore')
def data_loader(files):
out = []
for file in tqdm(files):
data, fs = librosa.load(file, sr = None)
out.append(data)
out = np.array(out)
return out
Xtrain = glob(data_dir + 'train/*.wav')
Xtrain = data_loader(Xtrain)
Ytrain = pd.read_csv(data_dir + 'train_answer.csv', index_col='id')
submission = pd.read_csv(data_dir + 'submission.csv', index_col='id')
print(Xtrain.shape, Ytrain.shape)
time.sleep(1)
Xtest = glob(data_dir + 'test/*.wav')
Xtest = data_loader(Xtest)
Xtrain = Xtrain.astype('float32')
Xtest = Xtest.astype('float32')
print(Xtrain.shape, Ytrain.shape, Xtest.shape, submission.shape)
언제나 그랬듯 비슷한 단계이다. 이번 대회는 음성 데이터를 다루는 대회여서, 데이터를 받으면 train 폴더 안에는 약 10만 개의 음성 파일이 wav 파일로 저장되어있고, test 폴더에는 1만 개의 음성 wav 파일이 들어있다.
wav 파일을 처음 다뤄보아서 어떻게 해야할지 손도 못대고 있던 와중에 데이콘에서 제공한 baseline 코드가 올라왔다. Scipy 를 이용해서 wav 파일을 불러오는 코드였다. 코드를 약간 바꿔서 librosa 패키지로 음성파일을 불러왔다.
Scipy 와 librosa 는 음성을 로딩한 결과물이 다른데, scipy에서는 +-30000 으로 원래의 값이 그대로 담겨있는 numpy array 가 생겼고, librosa 는 로딩된 데이터를 자동으로 +- 1 의 범위로 normalize 되어서 로딩되었다. 그래서 이렇게 느린거였나
모델을 만들면서는 RNN 만 빼고 1D CNN, MFCC, Mel-Spectrogram 3가지를 시도해보았었다. RNN 만들줄몰라요 1D-CNN 으로 원래 음성 파일을 그대로 다루는것 보다, MFCC 가 결과가 더 좋았고, MFCC 보다는 Spectrogram이, Spectrogram 에서도 원래 스펙트로그램인 Mel Power Spectrogram 보다 이 값들을 dB로 바꿔준 dB Mel Spectrogram (그냥 이름 붙임) 이 결과가 제일 좋았다.
데이콘에 코드 공유를 올리면서도 적어두었는데, 이번 대회에서는 음성 데이터의 ㅇ 자도 모르던 내가 코드 공유해주신 고수분들의 덕을 톡톡히 봤다고 해야 할 것 같다. 출처 : 우승하신 JunhoSun 님의 설명글 (from 데이콘 코드 공유)
'마지막으로 spectrogram과 melspectrogram의 해상력에 대해 설명하겠습니다. win_length가 커질수록 주파수 성분에 대한 해상력은 높아지지만, 즉 더 정밀해지지만, 시간 성분에 대한 해상력은 낮아지게 됩니다. 즉, 더 정밀한 주파수 분포를 얻을 수 있으나 시간에 따른 주파수 변화를 관찰하기가 어려워집니다. 반대로 win_length가 작은 경우에는 주파수 성분에 대한 해상력은 낮아지지만, 시간 성분에 대한 해상력은 높아지게 됩니다. 따라서 적절한 값을 찾는 것이 중요합니다.' - JunhoSun / 음성 신호 기본 정보 / (월간 데이콘 6 우승)
나의 능력으로 적절한 값 하나를 찾아낼 수는 없을 것 같아서 데이터를 여러 개 만들어서 합치기로 했다. 딥러닝은 나보다 똑똑하니까. 몇개의 mel spectrogram 을 만들다보니, 이 스펙트로그램의 크기는 hop_length 와 n_mels 로 결정된다는 것을 찾을 수 있었다.
이 값들에 대한 설명도 위 링크에서 내용을 찾아볼 수 있었다.
n_fft : win_length의 크기로 잘린 음성의 작은 조각은 0으로 padding 되어서 n_fft로 크기가 맞춰집니다. 그렇게 padding 된 조각에 푸리에 변환이 적용됩니다. n_fft는 따라서 win_length 보다 크거나 같아야 하고 일반적으로 속도를 위해서 2^n의 값으로 설정합니다.
win_length : 이는 원래 음성을 작은 조각으로 자를 때 작은 조각의 크기를 의미합니다. 자연어 처리 분야에서는 25m의 크기를 기본으로 하고 있으며 16000Hz인 음성에서는 400에 해당하는 값입니다.
hop_length : 이는 음성을 작은 조각으로 자를 때 자르는 간격을 의미합니다. 즉, 이 길이만큼 옆으로 밀면서 작은 조각을 얻습니다. 일반적으로 10ms의 크기를 기본으로 하고 있으며 16000Hz인 음성에서는 160에 해당하는 값입니다.
n_mels : 적용할 mel filter의 개수를 의미합니다.
아하. 처음 보는 말들이다. 이중에서 이 win_length 의 값에 따라서 시간성분 vs 소리성분 어느 것을 더 잘 뽑아낼 수 있느냐 가 결정된다고 한다. 32, 40, 64, 128 의 값들 중에서 n_mels 를 최대한 많이 하려고 했는데, 의 n_mels 가 128개가 되었을때는 에러가 나고 있었다.
Empty filters detected in mel frequency basis. Some channels will produce empty responses. Try increasing your sampling rate (and fmax) or reducing n_mels. warnings.warn('Empty filters detected in mel frequency basis.')
라고 하는데, 나의 경우 4개의 mel spectrogram 모두에서 에러메시지가 출력되지 않는 가장 큰 값이 64였어가지고 64개로 설정했다.
이게 하나하나 처리하다 보니 속도가 정말 느리다. Xtrain, Xtest를 합쳐서 4개 채널을 가진 mel spectrogram 으로 만들어주고, 케라스에 넣기 위해 Z-Score Normalization을 했다.
3. Build Model & Train
import keras
import keras.backend as K
from keras.models import Model, Sequential
from keras.layers import Input, Convolution2D, BatchNormalization, Activation, Flatten, Dropout, Dense, Add, AveragePooling2D
from keras.callbacks import EarlyStopping
from keras.losses import KLDivergence
from sklearn.model_selection import train_test_split
from keras.optimizers import Nadam
def mish(x):
return x * K.tanh(K.softplus(x))
def eval_kldiv(y_true, y_pred):
return KLDivergence()(np.array(y_true).astype('float32'), np.array(y_pred).astype('float32')).numpy()
케라스를 불러오고, KL-Divergence 를 계산할 수 있게끔 함수도 만들었다.
def build_fn():
dropout_rate=0.5
model_in = Input(shape = (Xtrain_dbmel.shape[1:]))
x = Convolution2D(32, 3, padding='same', kernel_initializer='he_normal')(model_in)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(32, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(32, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Convolution2D(64, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(256, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(64, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(256, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(64, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(256, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Convolution2D(128, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(512, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(128, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(512, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(128, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(512, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Flatten()(x)
x = Dense(units=128, kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Dropout(rate=dropout_rate)(x)
x = Dense(units=128, kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x_res, x])
x = Activation(mish)(x)
x = Dropout(rate=dropout_rate)(x)
model_out = Dense(units=30, activation='softmax')(x)
model = Model(model_in, model_out)
model.compile(loss=KLDivergence(), optimizer=Nadam(learning_rate=0.002))
return model
build_fn().summary()
Model Summary
Convolution 의 필터 수를 32, 64, 128, 256, 512 이렇게 5스텝으로 늘어나게끔 구성했다. Convolution 과 BatchNormalization 은 빅맥과 콜라처럼 한 세트로 보고 같이 묶었다. 이 모델을 만들던 시기에 ResNet 에 대해서 알게 되었다. 단순히 이전 레이어의 값을 뒷 레이어에 더해주는 행동 하나로, 깊은 신경망에서 학습이 더 잘된다고? 나도 얼른 적용해보았다. 어떻게 생겼는지 찾아도 보고, 따라해본다고 따라했는데, 비슷하게 따라한 것 같지는 않다. 그냥 텐서 크기가 같은 적절한 위치에서 뽑고, 더하고. 근데 나중에 CNN 깊게 만들때도 이거 있고 없고 차이가 '아주 약간' 났었다.
필터 수가 256, 512 일때는 ResNet 의 BottleNeck 구조를 이용했다. 기본적으로 Convolution 은 선형 연산이기 때문에, 나처럼 ConvConvConv 를 연속해서 하면 똑같은거라고 하지만 그냥 '최종적인 필터 수 256 (또는 512) 이면서, 파라미터 갯수 줄이기) 가 목적이었어서 그냥 ConvConvConv 를 적용해보았다. 그냥 BottleNeck 없이 Convolution 을 했으면 어떨까 궁금하다. 데이터가 크고 많을 수록 적합에 필요한 파라미터도 많을 것이기 때문에... 해볼만한 시도였던 것 같다.
num_models=15
model_list=[]
for i in tqdm(range(num_models)):
model = build_fn()
model.fit(Xtrain_dbmel, Ytrain, epochs=187, batch_size=16)
model_list.append(model)
model.save(f"model_{i}.h5")
이렇게 모델을 15개를 만들었다. 위 모델은 단일 모델을 만들면서 실험하면서 가장 점수가 좋았던 모델이고, early stopping 을 걸면서 에폭수 187 을 찾고, 배치 사이즈도 32, 16 을 했을때 16이 점수가 더 좋았어서 최종 선택했다.
RTX 2060 Super(8GB) 그래픽카드로 모델을 1개 학습시키는데 약 9시간 30분이 걸렸다. 코드는 이렇게 15개를 한번에 넣고 실행했지만, 실제로는 5개 하고 제출하고, 5개 더하고, 제출하고 했는데, 각각 결과는
5개 단순 평균 : 0.41778
10개 단순 평균 : 0.40481
정도이다.
preds = np.zeros(shape=submission.shape)
train_preds = np.zeros(shape = Ytrain.shape)
train_preds_list=[]
test_preds_list=[]
score_list=[]
for model, i in zip(models, range(len(models))):
a = model.predict(Xtrain_dbmel)
b = model.predict(Xtest_dbmel)
eval_score = eval_kldiv(Ytrain, a)
print(f"Model {i+1} Evaluation Score : {eval_score}")
train_preds = train_preds + a
preds = preds + b
train_preds_list.append(a)
test_preds_list.append(b)
score_list.append(eval_score)
train_preds = train_preds / len(models)
preds = preds / len(models)
print(f"\nMean Predictions Evaluation Score : {eval_kldiv(Ytrain, train_preds)}")
simple_average = pd.DataFrame(preds, index=submission.index, columns=submission.columns)
simple_average.to_csv('15 Average Ensemble model.csv')
simple_average.head(10)
예측 결과물들을 단순 평균을 내는데, 단순 평균만 해도 점수가 확 좋아지는 것을 확인할 수 있었다.
와우~~ 이렇게 점수가 확 좋아진것은 KL-Divergence 의 특성 때문인 것 같다.
KL-Divergence 는 맞춰야 할 값을 잘 못맞추더라도, 조금이라도 값을 잡고, 안잡고에 따라서 점수가 확 차이가 난다고 한다. 아무래도 평균을 내면, 조금이라도 값을 잡는 경우가 많아지기 때문이라고 생각한다.
15개 예측값들의 최종 평균 점수는
Simple Average of 15 Predictions
Public LB : 0.399484
Private LB : 0.39202
4. 마지막으로 할 말
으아으아으아으아감사합니다유ㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠ
처음으로 상금을 받았다. 운도 잘 따라준 것 같고, 내 능력 안에서 내가 해야하는 노력도 할만큼 했다고 생각한다. 코드 검증도 끝나고, 계약서도 쓰고, 최종적으로 9월 8일에 상금을 받았다. 불과 1년 반 전까지만 해도 나는 간신히 타이타닉 코드 따라 치면서 외우고, 손에 파이썬이란것을 처음으로 익히고 있었던 중이었는데, 저번 대회부터 랭킹 안에도 들었고, 이제는 돈도 받아봤다! 원래는 게이밍 노트북에(i5-8세대, GTX 1060) 램을 16G 로 업그레이드하고 1TB HDD 를 가상메모리용으로 두고 하던 중이었는데, 너무 느려 터지고, 데이터 불러오는것도 한세월, 한 에포크 도는거 두세월씩 걸려버리니까 너무 화가 나서 반드시 상금 타겠다는 각오로 들고있던 돈을 모두 때려 넣어서 컴퓨터를 바로 새로 샀다. 역시 귀족학문
그냥... 뭐...음... 아직까지는 이렇게 대회하는 것이 재미있다. 이걸로 일을 하게 된다면 어떻게 될까는 아직 잘 모르겠지만, 전과도 일단은 보류중이기 때문에 머신러닝 대회는 정말 취미가 된 상태지만, 아직까지는 대회 하는게 재미있다. 앞으로도 좀 더 잘 해봐야겠다.
대회가 끝이 났다. 사실 끝이 난지는 좀 됐는데, 차일피일 미루다가 코드 리뷰를 이제야 쓰게 되었다.
총 699팀 참가 신청, 315팀 제출, 그 중에서 17위. 처음으로 Top 10% 안에 들어서 랭킹 포인트...를 받았다!
결론을 말하자면, 내가 처음으로 랭킹 포인트를 받은 대회라서 기억에 오래 남을 것 같다. 캐글에 도전하면 세계의 고수들한테 매일같이 얻어터지고(?) 돌아오던 나였는데, 처음으로 상금은 아니지만 대회 보상으로 무언가를 받았다! 대회 끝나고, Private 리더보드가 공개되자마자 인스타에 기쁨의 절규글을 올리던 기억이 아직도 난다.
데이콘에서 무슨 이벤트? 라고 해서 후드집업이었나 를 준다 해서 바로 올렸지만, 블로그에 사적으로 코드를 올리는 것은 (내 코드여도) 뭔가 문제 될 수도 있을 것 같아서 혼자 겁먹고 기다리다가 드디어 쓴다. (약관 안 읽어보고 회원가입하다가 뒤통수 맞는 그런 느낌적인 느낌..?)
나름 도메인 지식을 찾아본다고 하긴 했는데, 다른 사람들의 코드를 보니까 좀 더 공부를 많이 해 볼걸 그랬다. 더이상 떠오르는 게 없어서 다짜고짜 스태킹 앙상블부터 시작했는데, 돌아보니까 이게 최고의 시간낭비이며, 점수를 더 올리지 못했던 원인인 것 같다. 'Good models means Good Features!'라는 캐글 짤방을 지나가다가 어디서 본 적이 있는 것 같은데, 이 대회로 피쳐 엔지니어링의 중요성을 다시 제대로 느낀 것 같다. 다음엔 더 잘해봐야지. 포기하지 말고...
여기에 내가 생각한 대로 적어놓았다. 적외선 분광분석법을 이용해서, 뇌 내 성분(hhb, hbo2, ca, na)의 농도를 파악하는 것이다.
1. Load Data
import os
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import time
import warnings ; warnings.filterwarnings('ignore')
from tqdm import tqdm
from sklearn.preprocessing import Normalizer
from sklearn.multioutput import MultiOutputRegressor
from scipy.stats import norm
from sklearn.model_selection import cross_val_score, train_test_split, cross_val_predict
from sklearn.metrics import mean_absolute_error
import random
import shap
import optuna
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
from catboost import CatBoostRegressor
from sklearn.tree import ExtraTreeRegressor
처음에 대회 데이터를 보고 바로 신경망으로 접근해야겠다고 생각하고 MLP 모델을 만들기 시작했었다. 그런데 아무리 해도 점수가 1.6~1.7 이하로 잘 나오지가 않아서 Tree 모델 4개를 만들어야겠다고 생각했다. (그리고 이 생각이 들고 얼마 후에 데이콘에서 Baseline 코드가 올라왔는데, xgboost로 4번 fit 해서 제출하는데 내 신경망 점수를 바로 짓밟아버렸다...) 난 정말 신경망을 못 만드나 보다.
기본 모델로 LightGBM과 sklearn의 MultiOutputRegressor 를 사용했다. sklearn 의 MultiOutputRegressor는 타겟 값이 여러 개일때 인자로 받은 한개의 모델을 여러 번 fit 시켜서 여러개 column 들을 뱉는 구조이다. 여기서는 타겟변수가 4개니까, 4번 학습을 한다. 파라미터를 대충 튜닝해서 살짝 underfitting 상태가 될 수 있도록 가볍게 튜닝을 하고, EDA 과정 중에서 반복적으로 사용했다. 이 'multi_model' 의 점수가 좋아지면 채택하고, 좋아지지 않으면 폐기하고 하는 식으로 반복했다.
def model_scoring_cv(model, x, y, cv=10, verbose=False, n_jobs=None):
start=time.time()
score=-cross_val_score(model, x, y, cv=cv, scoring='neg_mean_absolute_error', verbose=verbose,
n_jobs=n_jobs).mean()
stop=time.time()
print(f"Validation Time : {round(stop-start, 3)} sec")
return score
model_scoring_cv 함수를 만들어서 10 fold 교차 검증을 할 수 있도록 했다. 여러번 제출한 결과, 10 fold 교차 검증 점수가 리더보드 점수와 크게 차이가 나지 않아서 이 점수를 믿고 사용하기로 결정했다.
Train 데이터와 Test 데이터의 차이를 보고자 만든 Adversial validation 함수이다. Train 데이터에 대해서는 1을 타겟값으로 가지고, Test 데이터는 0을 타겟값으로 가지고, 이를 머신러닝으로 예측한다. F1 Score와 AUC를 구해서, 이 값이 0.5에서 크게 벗어나면, 내가 방금 한 데이터 전처리가 Target Leakage를 가져왔구나 생각하고 수정했다.
적외선 분광분석법 실험은 흡수 분광분석 실험이므로, 처음 쏜 빛에 비해서 특정 파장이 몇% 감소했는지를 확인하기 위해 원래 파장과 측정 파장의 비율을 변수로 추가했다.
3.4 ) gap
from sklearn.preprocessing import Normalizer
normalizer=Normalizer()
all_data = pd.concat((Xtrain, Xtest))
data = all_data.copy()
all_data[src_list] = normalizer.fit_transform(all_data[src_list])
Xtrain[src_list] = all_data[:len(Ytrain)][src_list]
Xtest[src_list] = all_data[len(Ytrain):][src_list]
del all_data
gap_feature_names=[]
for i in range(650, 1000, 10):
gap_feature_names.append(str(i) + '_gap')
alpha=pd.DataFrame(np.array(Xtrain[src_list]) - np.array(Xtrain[dst_list]), columns=gap_feature_names, index=train.index)
beta=pd.DataFrame(np.array(Xtest[src_list]) - np.array(Xtest[dst_list]), columns=gap_feature_names, index=test.index)
Xtrain=pd.concat((Xtrain, alpha), axis=1)
Xtest=pd.concat((Xtest, beta), axis=1)
print(Xtrain.shape, Ytrain.shape, Xtest.shape)
마찬가지로 원래 파장과 측정된 파장의 차이를 변수로 추가했다.
실험을 하면서, 데이터의 Normalization 이 필요할 것 같다고 생각했었다. 원래 파장은 값이 잘 나와있는 반면, 측정 파장은 대부분 값이 막 1e-10까지 작아서, 비교했을 때 너무 형편없는 수준이 되지 않을까... 해서, Normalize 하고 비율을 구하고, 차이를 구해보고, 아니면 차이를 구하고 Normalize 해보고 했는데, 이렇게 Normalize 하고 차이를 구하는 게 Validation 점수가 제일 잘 나왔었다. 알고 했다기보다는, 검증 점수 잘 나오는 방향으로 계속 데이터를 수정했다고 봐야 맞을 것 같다.
3.5 ) DFT
alpha_real=Xtrain[dst_list]
alpha_imag=Xtrain[dst_list]
beta_real=Xtest[dst_list]
beta_imag=Xtest[dst_list]
for i in tqdm(alpha_real.index):
alpha_real.loc[i]=alpha_real.loc[i] - alpha_real.loc[i].mean()
alpha_imag.loc[i]=alpha_imag.loc[i] - alpha_real.loc[i].mean()
alpha_real.loc[i] = np.fft.fft(alpha_real.loc[i], norm='ortho').real
alpha_imag.loc[i] = np.fft.fft(alpha_imag.loc[i], norm='ortho').imag
for i in tqdm(beta_real.index):
beta_real.loc[i]=beta_real.loc[i] - beta_real.loc[i].mean()
beta_imag.loc[i]=beta_imag.loc[i] - beta_imag.loc[i].mean()
beta_real.loc[i] = np.fft.fft(beta_real.loc[i], norm='ortho').real
beta_imag.loc[i] = np.fft.fft(beta_imag.loc[i], norm='ortho').imag
real_part=[]
imag_part=[]
for col in dst_list:
real_part.append(col + '_fft_real')
imag_part.append(col + '_fft_imag')
alpha_real.columns=real_part
alpha_imag.columns=imag_part
alpha = pd.concat((alpha_real, alpha_imag), axis=1)
beta_real.columns=real_part
beta_imag.columns=imag_part
beta=pd.concat((beta_real, beta_imag), axis=1)
Xtrain=pd.concat((Xtrain, alpha), axis=1)
Xtest=pd.concat((Xtest, beta), axis=1)
print(Xtrain.shape, Ytrain.shape, Xtest.shape)
이산푸리에 변환을 적용한 값을 추가해주었다. 여기서 실수를 한 것이, 푸리에 변환 이후 나오는 결과물 (복소수) 에 abs 를 씌우면 되는걸, 괜히 실수부와 허수부로 쪼개서 변수를 70개를 추가해버렸다. 물론 안해봐서 정확한 결과는 모르지만, 아무리 생각해도 실수였던 것 같다. 대회 끝나고, 다른 대회의 다른 사람이 코드 공개한 걸 보았는데, 복소수에 abs 씌우면 되는걸.... 난 왜 이렇게 했을까, 대회가 끝나고 알게돼서 어쩔 수 없었다.
처음에 푸리에 변환을 여기서 써도 되나 싶어서 열심히 검색을 했었다. 시중에는 수많은 FTIR 장비들이 돌아다니고 있었고, 시계열 데이터가 아닌 경우에 푸리에변환을 사용하는 경우들을 확인할 수 있었고, 아 괜찮겠다 싶어서 바로 적용했다. 그리고 그 코드를 EDA 결과물이라고 코드 공유를 했는데... '왜 시계열이 아닌데 푸리에변환 썼냐, 뭔지도 모르는 데이터를 사용하는 건 개오바 아니냐, 열 별로 값을 보면 정규분포 아니냐' 하고 태클을 거시는 한 분이 있었는데, 이제 말하지만 이 분 때문에 너무 스트레스를 받았고 코드 그냥 삭제할까 싶었고, 괜히 올렸다 생각만 정말 많이 들었었다. 댓글 달면서 쓸 시간 없는데.. 코드 한 줄이라도 더 쓸 시간인데..
타겟변수가 4개이므로, 4개의 데이터 사본을 만들었다. 각각의 타겟 변수에 따라서 주로 사용할 파장 영역이 다를 것 같다 생각해서 Feature Selection을 다르게 진행하기 위해서였다.
def apply_chromosome(chromosome, x_train):
df = x_train.copy()
for col, apply in zip(x_train.columns, chromosome):
if apply == 0:
df = df.drop(columns=col)
return df
def scoring(model, x_train, y_train):
return -cross_val_score(model, x_train, y_train, cv=5, scoring='neg_mean_absolute_error').mean()
def make_chromosome_score(chromosome, model, x_train, y_train):
data= apply_chromosome(chromosome, x_train)
value = scoring(model, data, y_train)
return value
def choose_chromosomes(chromosomes_list, scored_list, factor, num_choose):
chromosome_pool = chromosomes_list.copy()
score_list = scored_list.copy()
chosen_chromosome=[]
new_score_array=np.array(score_list) + np.random.normal(0, np.array(score_list).std() * factor, size=len(score_list))
new_score_list = list(new_score_array)
for i in range(num_choose):
select_index = np.argmin(new_score_list)
selected = chromosome_pool[select_index]
del chromosome_pool[select_index]
del new_score_list[select_index]
new_score_array = np.array(new_score_list)
chosen_chromosome.append(selected)
return chosen_chromosome
def crossover(chromosome_list, score_list, next_pool_size, factor, num_choose):
child_pool = []
while len(child_pool) < next_pool_size:
best_parents=choose_chromosomes(chromosome_list, score_list, factor=factor, num_choose=num_choose)
parents = random.sample(best_parents, 2)
mom = parents[0]
dad = parents[1]
inherit = np.round(np.random.uniform(low=0, high=1, size=len(mom)))
child = []
for dna, i in zip(inherit, range(len(inherit))):
if dna==0:
child.append(mom[i])
else:
child.append(dad[i])
child_pool.append(child)
return child_pool
def mutant(pool, mutation_rate, mutation_size):
to_be_mutant = np.round(np.random.uniform(low=0, high=1, size=len(pool)) - (0.5 - mutation_rate))
which_child = np.where(to_be_mutant==1)[0]
for child_index in which_child:
mutation_info = np.round(np.random.uniform(low=0, high=1, size=len(to_be_mutant))-(0.5-mutation_size))
mutation_info = np.where(mutation_info ==1)[0]
for is_mutated in mutation_info:
if pool[child_index][is_mutated]==0:
pool[child_index][is_mutated] = 1
elif pool[child_index][is_mutated]==1:
pool[child_index][is_mutated] = 0
return pool
def next_generation(model, x_train, y_train, first_gen_chromosome, next_pool_size, factor, num_choose_parents,
mutation_rate, mutation_size):
score_list=[]
for chromosome in tqdm(first_gen_chromosome):
score = make_chromosome_score(chromosome, model, x_train, y_train)
score_list.append(score)
print("Calculating Current Generation's Score")
current_generation_best_chromosome = first_gen_chromosome[np.argmin(score_list)]
current_generation_best_score = np.min(score_list)
current_generation_mean_score = np.mean(score_list)
print(current_generation_best_chromosome)
print(f"\nBest Score : {current_generation_best_score}")
print("Generating Child pool")
child_pool = crossover(first_gen_chromosome, score_list, next_pool_size=next_pool_size,
factor=factor, num_choose=num_choose_parents)
print("Generating Mutation childs")
next_generation_chromosomes = mutant(child_pool, mutation_rate=mutation_rate, mutation_size=mutation_size)
print('Done!')
return next_generation_chromosomes, current_generation_best_chromosome, \
current_generation_best_score, current_generation_mean_score
def feature_select_ga(model, x_train, y_train, num_epoch, pool_size, factor=0.1,
num_choose_parents=3, mutation_rate=0.05, mutation_size=0.05, plot_score = True):
#factor : percentage of noise added to calculated score
#if too large, bad scoring parents could be selected since score order changes
#mutation_rate : percentage of childs to be mutated
#mutation_size : percentage of genes to be mutated
pool_size = pool_size
pool=[]
for i in range(pool_size):
chromosome = np.round(np.random.uniform(low=0, high=1, size=x_train.shape[1]))
pool.append(chromosome)
best_features=[]
best_scores=[]
mean_scores=[]
for i in tqdm(range(num_epoch)):
pool, gen_best_features, gen_best_score, gen_mean_score = next_generation(model, x_train, y_train, pool,
next_pool_size=pool_size,
factor = factor,
num_choose_parents=num_choose_parents,
mutation_rate=mutation_rate,
mutation_size=mutation_size)
best_features.append(gen_best_features)
best_scores.append(gen_best_score)
mean_scores.append(gen_mean_score)
final_score_list=[]
for chromosome in tqdm(pool):
score = make_chromosome_score(chromosome, base_model, x_train, y_train)
final_score_list.append(score)
last_generation_best_chromosome = pool[np.argmin(final_score_list)]
last_generation_best_score = np.min(final_score_list)
last_generation_mean_score = np.mean(final_score_list)
best_features.append(last_generation_best_chromosome)
best_scores.append(last_generation_best_score)
mean_scores.append(last_generation_mean_score)
if plot_score==True:
figure, ax1 = plt.subplots(nrows=1, ncols=1)
figure.set_size_inches(10, 7)
sns.lineplot(data=np.array(best_scores), ax=ax1, label='best')
sns.lineplot(data=np.array(mean_scores), ax=ax1, label='mean')
best_chromosome = best_features[np.argmin(best_scores)]
df = apply_chromosome(best_chromosome, x_train)
print(f"best_features = {list(df)}")
return df
유전 알고리즘이란 것을 처음 들어보았다. 나무위키에 쓰여있는 유전 알고리즘 설명을 보고 대충 구현해 보았다. 사용하는 변수는 1, 사용하지 않는 변수는 0을 주고, 최고의 [1,0,0,0,1,1,1,1,1,0....]을 찾은 다음에 데이터에 적용시키면 각각의 타겟변수에 대해 필요한 변수를 잘 선택할 수 있을 거라고 생각했다.
Public LB에서는 0.94532로 21위로 기록되어 있었는데, Private LB 에서는 0.92553으로 17위로 올라와서 대회를 마무리할 수 있었다.
대회 종료 이후 다른 사람들의 코드를 보았는데, 다들 정말 피쳐 엔지니어링에 신경을 많이 쓴 것 같았고, 단일 모델 dart 로도 점수가 나보다 더 잘 나왔다. 보고 현타가 좀 왔었는데, 정말 내가 쓸데없는 짓 하느라 시간을 많이 끌었구나 생각이 정말 정말 정말로 많이 들었다. 그래도, 상위 10% 안에 드는 것이 목표였는데, 목표도 달성했고, 처음으로 무언가 상금은 아니지만 리턴을 받은 대회여서 너무 좋았다!
'이온 스위칭'이라는 이름인데, 고등학교 때 어깨너머로 배운 생명과학2가 생각이 났다. 흥분의 전도 배울 때, 나트륨 통로, 칼륨 통로, 나트륨 칼륨 펌프 이렇게 배웠던 것 같다. 큰 도움은 되지 않지만, 약간의 domain knowledge를 기억해내자면,
세포 내부는 기본적으로 약한 음전하를 띄고, 세포 외부는 양전하를 가지고 있는 상태이다. 이때의 전위차를 휴지 전위 라고 한다. 이때 세포에 자극이 주어졌을 때, 세포막에 있는 통로가 열리면서 세포 외부의 양전하를 띄는 이온들이 세포 내부로 들어오게 되면서 세포 내부의 전하가 + 가 된다. 이때 + 전하의 값을 활동 전위, 이 활동 전위가 나타나는 현상을 탈분극이라고 한다.
깜짝 놀란 세포는 다시 휴지전위로 돌아가고자 들어왔던 양이온들을 다시 내보낸다. 이를 재분극이라고 한다. 이때 일시적으로 휴지 전위보다 전하량이 더 낮아지는 과정이 있는데, 이런 현상을 과분극이라고 한다. 하지만 곧 보통의 휴지 전위 상태로 돌아온다.
데이터를 받아보면 'time, signal, open_channels' 딱 3개의 변수만 주어져있다. 이중 open_channels 가 우리가 예측해야할 타겟 변수이다. time 은 말 그대로 시간이고, 총 10개의 실험데이터가 1개 실험당 50초, 0.001초 단위로 나누어져 있다. 총 데이터 행 수는 5000000행이다. time 데이터는 순서대로 0.001초 단위로 주어지지만, 각 10개의 실험은 독립적으로 실행된 것이라고 주최측은 밝힌 바 있다. signal 은 이 0.001초 단위로 기록된 세포의 전위 상태를 의미하고, open_channels는 그때 측정된 열려있는 이온 통로의 갯수이다. 아무래도 signal의 값이 커질수록 세포가 더 강한? 많은? 자극을 받았다는 의미이고, 더 많은 이온 통로가 열려서 양이온들이 많이 세포로 들어갔기 때문에 이런 값이 관측되었을 것이다. 다만, 막상 시각화를 해 보면 아주 정확하게 딱딱 나눠지지는 않는다.
측정 공식은 'F1-macro' 방식이다.
일단 현재 랭킹은 768팀 중에 411등이다. 역시 사람들 개 잘한다. LightGBM을 쓰는 사람도 있고 CNN, U-Net 다른 딥러닝 모델들도 쓰이고 있... 는 것 같다. 한번 열심히 해봐야지.
타이타닉 대회를 마무리하고, 다음으로 도전해볼 만한 캐글 컴퍼티션이 뭐가 있을까 찾아보다가 이 집값을 예측하는 대회를 찾았다. 오호, 집값을 예측한다고? 나도 그럼 부동산으로 돈 한번 땡겨 볼 수 있을까? 하는 생각에 신나게 대회 참가 버튼을 눌렀다.
타이타닉보다는 훨씬 데이터도 많고, (하지만 여전히 적음) 다루기도 어렵다. 그리고 타이타닉과 같은 'Classification', 분류 문제가 아니라 'Regression' 회귀 문제이다. Regression 문제는 정답이 어떤 실수 형태로 주어져서, 이 값을 예측하는 문제이다. 반면 Classification 문제는 타이타닉처럼 데이터가 어떤 종류인가 (생존인가, 사망인가) 를 맞추는 문제이다. 그럼 생존 확률을 맞추라그러는거는 뭐냐? 여기서 LogisticRegression 을 처음 들어본 사람은 멘붕이 온다. LogisticRegression은 이름에는 Regression 이라고 되어 있지만, 사실은 Classification 문제에 사용한다. 쉽게 생각하면, 이 LogisticRegression은 해당 클래스의 확률 값을 찾는 Regression이어서 이름에는 Regression 이 들어가지만, Classification 문제에 사용된다고 생각하면 된다. Classification 이어도, 문제에 따라서는 확률 값을 제출하기를 요구하는 문제들도 있다.
1. 데이터 로드 (Load Data & Packages)
import pandas as pd
import numpy as np
from scipy.stats import norm
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import warnings; warnings.simplefilter('ignore')
마찬가지로 데이터를 불러와준다. 주피터 노트북 파일과 저 csv 파일들이 같은 폴더 안에 있을때 잘 작동한다. 여기서는 data 라는 변수에 train을 다시 저장했는데, 데이터를 보면 변수가 매우 많고, 손을 많이 댈 예정이라서 꼬일 수도 있기 때문에 data 라는 변수를 새로 만들었다.
print 문의 결과를 보자면
(1460, 80) (1459, 79) (1459, 1) 이라고 출력될 것이다.
총 1460 행의 train 데이터를 가지고 1459 행의 test 데이터의 집값을 예측해야 한다. 이때 변수는 79개... 로 꽤나 많이 주어진다. 손이 많이 갈 것이다.
2. 데이터 분석하기
2.1. 타겟 변수 확인 (Distribution of Target)
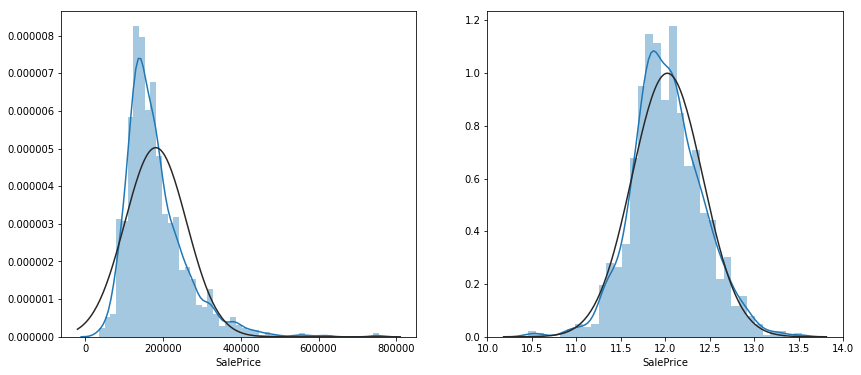
이번 대회는 Regression 문제인 만큼 더더욱 타겟 변수의 분포를 확인해야 할 필요성이 생겼다. 코드를 보면,
좌 : 타겟 변수의 분포, 우 : 타겟변수에 로그를 취한 분포. 우측이 더 정규분포에 가깝게 보인다.
왼쪽 그래프를 대충 보아도 약 400000 정도 값이 중심인 것을 알 수 있다. 하지만 많은 데이터가 400000보다 왼쪽으로 치우쳐 있는데, 이렇게 데이터의 분포가 비대칭인 정도를 'Skewness' 라고 한다. 한국어로 번역하면 '왜도' 라고 한다. 이 Skewness의 꼬리가 오른쪽으로 길게 있으면 'Right Skewed' 또는 'Positive Skewed', 왼쪽으로 길게 있으면 'Left Skewed' 또는 'Negative Skewed' 라고 한다. 오른쪽이든 왼쪽이든 심한 비대칭은 머신러닝 알고리즘이 학습을 잘 하지 못하도록 방해하는 요소 중 하나이다. 대부분의 데이터가 왼쪽에 있다면, 오른쪽 꼬리 부분은 데이터가 적어서 학습이 잘 안될 가능성이 있다. 따라서 예측 결과물도 의심할 수 밖에 없다. 이런 상황에서 'Right Skewed' 를 해결하는 대표적인 방법이 바로 해당 변수에 로그를 취하는 것이다. 키야~ 로그에 취한다~
확실히 로그를 취하면 비대칭도가 줄어들고, 정규분포에 가깝게 데이터가 분포되어 있는 것을 확인할 수 있다. 우리는 이렇게, 머신러닝에게 로그를 취한 값을 타겟 변수로 주어서 예측하게끔 한 다음에, 마지막에 제출할 때만 지수 계산을 해서 제출하면 그만이다.
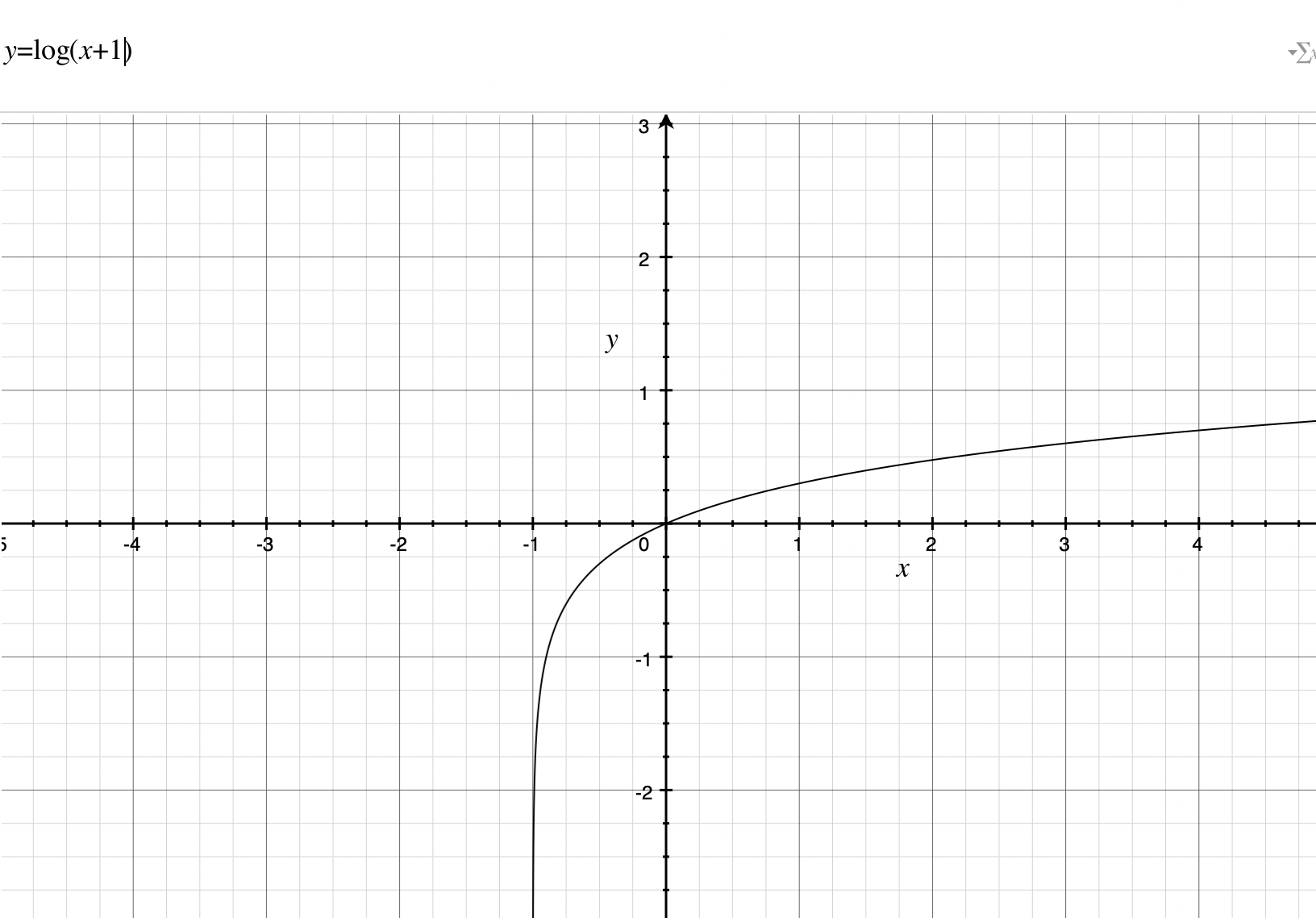
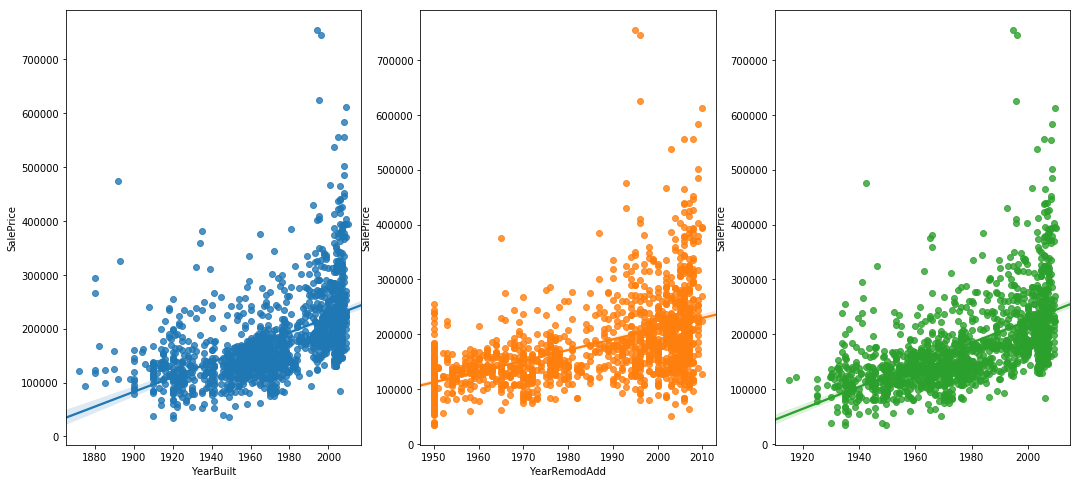
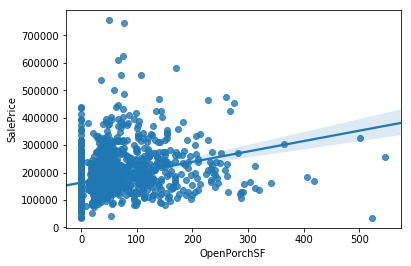
어떤 두 개의 변수 A와 B가 있을때, 변수 A 의 값이 커질때, 변수 B의 값도 커지면 이 둘은 양의 상관관계를 갖고 있다고 한다. 반대로, 변수 A의 값이 커질때, 변수 B의 값이 작아지면 이 둘은 음의 상관관계를 갖고 있다고 말한다. 그렇다면 상관관계가 0인 경우는? 그렇다. 변수 A가 어떻게 움직이든 변수 B에 별 영향이 없는 경우를 말한다. 이 상관관계를 측정하는 값을 '상관계수' 라고 말하고, 우리는 주로 '피어슨 상관계수' 를 이용해 상관계수를 분석한다. 이 그래프는 타겟 변수인 'SalePrice' 와 가장 큰 상관관계를 가진 40개의 변수를 표시하는 그래프이다. 그래프를 뜯어보면, 변수 'OverallQual' 이라는 변수가 상관계수 0.79로 타겟변수와 가장 큰 상관관계를 가지고 있는 것으로 나타났다. 전반적으로 OverallQual 이 증가하면, 집값도 증가한다고 볼 수 있다는 뜻이다.
sns.regplot(data['GrLivArea'], data['SalePrice'])
GrLivArea 와 SalePrice 의 관계를 표시한 그래프
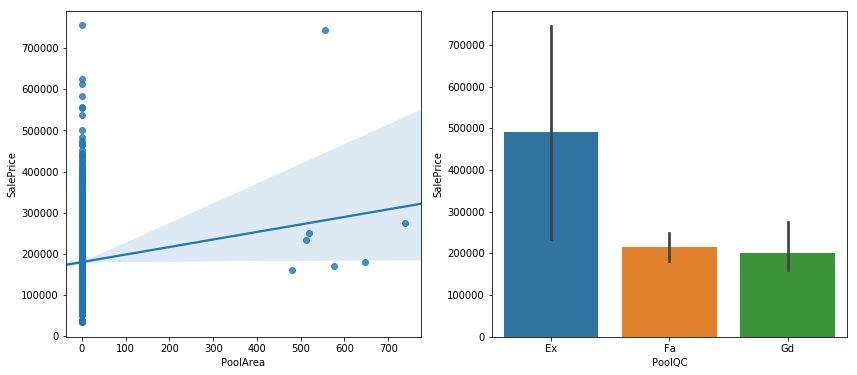
두번째로 큰 상관계수를 가진 'GrLivArea' 의 그래프를 띄워보면 위와 같다. 전체적으로 'GrLivArea' 가 증가하면 집값도 증가한다는 것을 확인할 수 있다. 다만 눈에 약간 거슬리는 부분이 있는데, 오른쪽 아래에 점 두개이다. 저 점들의 분포는 그래프 상의 저 직선으로 표현이 가능한데, 오른쪽 아래에 있는 저 두 점들은 전혀 다른 결과를 보여주고 있다. 저런 데이터들을 '이상치' (Outlier)로 간주하고 삭제해주는 것도 머신러닝의 정확도를 높일 수 있는 방법 중 하나이다.
타겟 변수를 미리 Ytrain으로 빼서 저장하고 위에서 말한듯이 로그를 씌웠다. 로그를 씌우는데 +1 을 해주는 이유는 log0 의 값이 없기 때문이다. 공짜 집은 없겠지만 만약 Ytrain의 값중 하나가 0이라면..? log0은 마이너스 무한대로 커지기 때문에 +1씩 해주어서 이를 방지한다. 이를 'log1p' 라고 하기도 한다.
log1p 의 그래프
2.3. 전체 데이터에서 결측치 확인 (Check Missing Values)
이 데이터는 사실 상당히 깔끔하지만, 막상 꺼내어 보면 결측치가 참 많이 있다. 이는 캐글에서 데이터를 다운로드 받을 때 같이 딸려오는 'data description.txt' 파일을 읽어보면, 집에 해당 시설물이 없는 경우는 결측치로 처리되어 있음을 알 수 있다. 물론 중간에는 진짜 결측지도 있겠지만, 없는 경우가 더 많다. 따라서 결측치를 처리하는 방법이 매우 간단하다.
cols=list(all_data)
for col in list(all_data):
if (all_data[col].isnull().sum())==0:
cols.remove(col)
else:
pass
print(len(cols))
list(all_data) 를 사용하면 all_data 라는 데이터프레임의 열 이름을 리스트로 만들 수 있다. 다음 코드는 반복문을 통해서 all_data 에서 해당 열에 결측치가 없으면 리스트에서 그 열의 이름을 지운다. 그러면 남은 리스트에는 결측치가 있는 변수 이름만 남아있을 것이다. print 문으로 출력해보면 아래 코드에 있는 이름들이 나올 것이다.
for col in ('PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'MasVnrType', 'MSSubClass'):
all_data[col] = all_data[col].fillna('None')
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath', 'MasVnrArea','LotFrontage'):
all_data[col] = all_data[col].fillna(0)
for col in ('MSZoning', 'Electrical', 'KitchenQual', 'Exterior1st', 'Exterior2nd', 'SaleType', 'Functional', 'Utilities'):
all_data[col] = all_data[col].fillna(all_data[col].mode()[0])
print(f"Total count of missing values in all_data : {all_data.isnull().sum().sum()}")
첫번째, 집에 해당 시설물이 없는 경우 (범주형 변수), 이때는 결측치를 'None' 이라는 문자열로 채운다. (이 작은 따옴표 없는 None 과 문자열 'None' 은 다르다!)
두번째, 집에 해당 시설물이 없는 경우(수치형 변수), 이때는 결측치를 0으로 채운다. 차고면적=0 이면 차고 없음 이런식으로 생각할 수 있다.
세번째, 해당 시설물이 없다고 보기 힘든 경우에 있는 결측치, 이때는 결측치를 해당 열의 최빈값으로 채운다. 집에 외벽 시설이 없을리는 없고, 집이 판매가 되었는데 거래 타입이 정해지지 않을리는 없다.
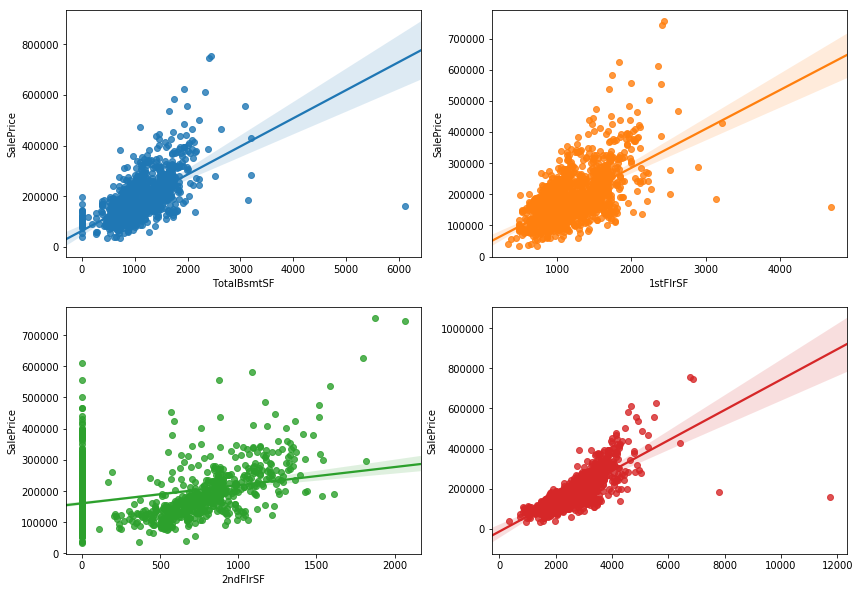
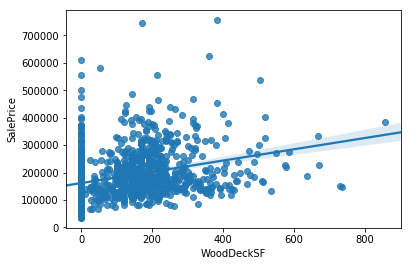
지하실, 1층, 2층 면적을 모두 합한 '총 면적' 이란 변수를 추가로 만들었다. 오른쪽 아래에 있는 그래프가 나머지 3개를 합한 면적을 나타낸 그래프인데, 상당히 타겟변수를 잘 설명할 수 있다. 상관관계도 꽤 높아보인다. 이는 총 면적이 증가하면, 집값이 더 비싸진다고 볼 수 있다. 이들을 더해서 'TotalSF' 라는 이름으로 저장해야겠다.
욕실 갯수는 'FullBath' 와 'HalfBath', 그리고 지하에 있는지 여부, 총 4개 열로 이루어져있었는데, 이들을 모두 더해 하나로 만들어 보았다. FullBath 는 욕조 및 샤워 시설이 포함되어있는 욕실이고, HalfBath는 변기와 세면대 정도 있는 간단한 욕실을 말한다. 이름에 맞게 FullBath는 1개로 카운트하고, HalfBath 는 0.5개로 카운트해서 모두 더했더니 다음과 같은 그래프를 얻을 수 있었다.
욕실 수의 총합
이를 보면 욕실 수가 많을수록 더 집값이 비싸진다고 볼 수 있다. (더 큰 집일수록 욕실수가 많을 것이라 생각한다). 하지만 여기서 특이한 점이 하나 있는데, 욕실 갯수가 5개, 6개인 집들은 막대그래프 위의 검정 세로선이 보이지 않는다. 에 이게뭐지? 할 수도 있지만, 저 검정 선은 편차를 의미한다. 그렇다면 편차가 없다는것이 무슨뜻이지? 값이 다른 데이터가 두개만 있어도 편차가 발생할텐데? 화장실 갯수가 5개, 6개인 집은 각각 하나씩밖에 없다는 뜻으로 볼 수 있다. 이들은 역시 outlier 로 판단하고 지워도 상관이 없다.
건축 연도와 리모델링 연도의 평균을 구하는것이 무슨 의미가 있나 할 수도 있다. 하지만 아주 의미가 없지는 않다! 건축 연도가 오래 되었어도, 최근에 리모델링을 하면 이 값이 높게 나왔을 것이고, 건축 이후 리모델링을 하지 않았다면 이 값은 아주 낮게 나왔을 것이다. 따라서 이 값이 높은 집들은 '지어진지 얼마 되지 않은 신축 건물 + 최근에 리모델링까지함' 에 가깝고, 이 값이 낮은 집들은 '오래된 건물 + 리모델링도 안함' 에 가까울 것이다. 그리고 이는 집값에 유의미한 영향이 있다고 초록색 그래프를 보면 판단할 수 있다.
데이터 설명을 보면 나와있지만 'MSSubClass' 는 사실 숫자로 이루어진 데이터지만, 각각의 숫자가 의미를 갖고있는 범주형 변수이다. 그리고 판매 연, 월도 역시 연산 개념을 적용하는데는 무리가 있다. 그래서 이들을 문자열로 바꿔주자.
나는 사람들이 집을 볼때, 1층을 쭉 둘러보고 '괜찮네', 2층을 보고 '별로네', 지하층과 차고를 보고 '좋네' 이런식으로 판단할 거라고 생각했다. 이 평가의 기준 점수는 사람마다 약간 다르겠지만, 해당 시설물을 종합적으로 보고 판단하는 행위는 모두가 비슷할 것이라 생각했다. 나는 그래서 집의 시설물들을 묶어서 점수를 매기기로 했다.
범주형 변수가 상당히 많은 데이터셋이다. 범주형 변수를 다짜고짜 1, 2, 3, 4, ... 로 인코딩해주면 머신러닝이 오해할 소지가 충분하기 때문에 일단 모조리 원핫 인코딩을 한다.
non_numeric=all_data.select_dtypes(np.object)
def onehot(col_list):
global all_data
while len(col_list) !=0:
col=col_list.pop(0)
data_encoded=pd.get_dummies(all_data[col], prefix=col)
all_data=pd.merge(all_data, data_encoded, on='Id')
all_data=all_data.drop(columns=col)
print(all_data.shape)
onehot(list(non_numeric))
3.2. 수치형 변수 (Numeric Feature)
수치형 변수는 비대칭이 너무 심해지지 않게끔, Right Skewed 가 크게 되어있는 데이터들에만 로그를 씌워 적절히 변형시켜준다.
numeric=all_data.select_dtypes(np.number)
def log_transform(col_list):
transformed_col=[]
while len(col_list)!=0:
col=col_list.pop(0)
if all_data[col].skew() > 0.5:
all_data[col]=np.log(all_data[col]+1)
transformed_col.append(col)
else:
pass
print(f"{len(transformed_col)} features had been tranformed")
print(all_data.shape)
log_transform(list(numeric))
그럼 이제 데이터를 나누는 일만 남았다. all_data 항목을 test 데이터의 갯수에 맞게끔 잘라서 따로 저장하면 된다.
원래 train 데이터의 갯수와 데이터를 가공한 Xtrain 데이터의 갯수가 1458 개로 동일하다. (위에서 'GrLivArea' 할 때 train 에서 두개를 지웠었다!)
4. 머신러닝 모델로 학습
from sklearn.linear_model import ElasticNet, Lasso
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from xgboost import XGBRegressor
import time
import optuna
from sklearn.model_selection import cross_val_score
from sklearn.metrics import mean_squared_error
머신러닝에 입문하는 사람들이라면 누구나 들어봤을, 모두가 머신러닝 입문용으로 시작하는 바로 '그' 경진대회이다. 그 이름은 타이타닉. 나도 타이타닉으로 머신러닝에 입문했었다. 지금은 약 1년 몇 개월 전의 일이네. 내가 지금까지 참가한 대회 중에서 가장 성적이 높은 대회이기도 하다...(눈물 주르륵 광광)
정확도 약 82.2% 라는 뜻이다
데이콘이라는 사이트에서도 타이타닉 컴퍼티션이 있다. 참고로 캐글에서 0.82296의 점수는 (2020년 3월 4일 기준) 16000여 명 중에서 471등을 기록하고 있다. 캐글의 타이타닉 대회에서는 점수 측정공식이 '정확도' 인 반면, 데이콘에서는 'RMSE' 를 사용한다. RMSE를 사용한다면, 아무래도 데이터를 사망 여부 (사망시 0, 생존시 1) 로 딱딱 떨어지게 예측하기보다는, 생존 확률 (0.6인경우, 60퍼센트의 확률로 생존 가능성) 로 결과물을 제출하는 것이 더 낫기 때문에, 코드의 마지막 줄만 바꾸어서 데이콘에 제출했더니 3위이다.
1등과 점수차이가 좀 나긴 하지만, 그래도 3등이다!
뭐 이런 튜토리얼성 경진대회 잘한다고 실력이 좋은, 뛰어난 데이터 사이언티스트의 싹이 보인다는 뜻은 당연히... 맞을 수도 있지만 아닐 가능성도 있다. 그래도 입문하면서 점수가 잘 나오면, 기분이 매우 좋다! 나는 처음 캐글을 시작하면서 랭킹이 바로바로 업데이트 되는 것을 보고 아주 환장을 하고 죽기살기로 덤볐었다. 랭킹 몇 등 올리는것이 당시 나에게는 세상 그 무엇보다도 재미있는 일이었다.
아무튼, 나는 이 코드를 이미 캐글에 수백 번 제출했었고, 내가 하는 스터디에서도 발표했었고, 캐글 노트북(캐글 커널) 에도 업로드를 했었고, 아주 수도 없이 우려먹었었지만, 이제 마지막으로 우려먹으려고 한다. 이 블로그에 나의 머신러닝에 관한 모든 기록을 담아서 보관할 예정이라서, 여기에도 업로드를 하려고 한다.
아마 구글 검색해서 나오는 코드들중에서는 내 코드가 가장 쉬울 거라고 생각한다.... 아무리 봐도 내 코드는 너무 쉬워보인다..
머신러닝에 입문하는 사람들에게 약간이나마 도움이 되었으면 합니다.
지식은 고여있으면 썩는 법이니까.
21.02. - 처음에는 리더보드가 test 일부만 가지고 채점되어서 0.82296이었는데, 현재는 test 전체를 이용해서 채점하기 때문에 점수가 바뀌었습니다. 0.79186이네요. 데이콘에서도 지금은 RMSE를 사용하지 않습니다!
1. 패키지 로드
import pandas as pd
import numpy as np
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
간단히 설명을 하자면
pandas : 데이터 (주로 행렬 데이터) 를 분석하는데 쓰이는 파이썬 패키지. 특히 표 데이터를 다룰때 거의 무조건 사용한다.
numpy : 선형대수 연산 파이썬 패키지. 그냥 수학 계산을 편하고 빠르게 할 수 있는 패키지라고 생각하면 쉽다.
%matplotlib.inline : 그래프를 주피터 노트북 화면상에 바로 띄울 수 있게 하는 코드. 근데 없어도 seaborn 그래프 잘만 되더라.
seaborn : 쉽고 직관적인 방법으로 그래프를 띄울 수 있는 패키지.
matplotlib.pyplot : matplotlib 라는 그래프 띄우는 패키지 중 일부. 나는 여러개의 그래프를 한 결과로 띄우고 싶을때만 주로 사용한다.
norm : 정규분포를 의미. 데이터의 분포 그래프를 띄울때, 이 norm 을 불러와주면 정규분포랑 손쉽게 비교해 볼 수 있다.
train.csv, test.csv, submission.csv 이 세 파일이 지금 작업하고있는 주피터 노트북과 같은 폴더 안에 있을 때 작동한다. 만약 다른 폴더에 있다면, '/Users/뭐시기/뭐시기/Desktop/train.csv' 처럼 경로를 지정해준다면 잘 열릴 것이다.
pd(판다스) 의 'read_csv' 라는 메소드를 이용해서 csv 파일을 쉽게 읽어올 수 있다. 'index_col' 은 해당 열을 (여기서는 승객번호) 인덱스로 사용할 수 있게끔 해준다. 이후에 데이터를 보면 알겠지만, 승객번호는 1번, 2번, 3번, .... 800몇번 이런식으로 쭉 증가하는 고유한 값이기 때문에 나는 이 열을 인덱스로 사용했다.
마지막 print 문을 실행하면 결과는 아마
(891, 11) (418, 10) (418, 1)
이라고 출력이 될 것이다. 이 괄호 안의 숫자들이 우리가 읽어온 데이터 행렬의 크기를 나타낸다. 표시되는건, (행 숫자, 열 숫자) 로 출력이 된다. 우리는 train.csv 에 있는 891명의 승객 데이터를 가지고, test.csv 에 있는 418명의 생존 여부를 예측해서 제출해야 한다는 의미이다.
3. 데이터 분석 시작
이제 남은 일은 내 입맛대로 데이터를 분석하고 요리하면 되는 것이다. 내가 행렬 데이터를 보면 항상 하는 순서가 있는데, 그 순서대로 해보겠다.
이렇게 데이터의 열에 '이름' 이 붙어있다면, 데이터를 분석할 때 상식적인 선에서의 '가설' 을 세우고 접근하는 방법이 있다. 예를 들면, 여성이 남성보다 생존 확률이 높을 것이다. 어린이들은 생존 확률이 높을 것이다. 라는 등의 가설을 세울 수 있겠다. 이는 경우에 따라서는 상당히 좋은 방법이다. 일반적인, 그니까 상식적인 수준에서 가설을 세울 수 있다면 데이터 분석 과정을 상당히 빠르게 해낼 수 있다. 다만, 데이터가 '익명화' 되어서 데이터 열에 이름이 없는 경우, 가설을 세우기가 상당히 어려워진다. 또한, 해당 분야의 배경지식이 필요한 전문 분야의 데이터일수록 가설 세우기는 더더욱 어렵게 된다. 전문 지식이 있으면 좀 낫겠지만. 하지만 1년 몇개월 간의 짧은 경험 상으로는 없다고 해서 크게 문제되지는 않았다. '컴퍼티션 진행하는데 배경 지식이 있으면 훨씬 쉬웠겠지만, 없어도 지장은 없다.' 정도의 느낌을 받았다.
3.1. 타겟 변수 확인
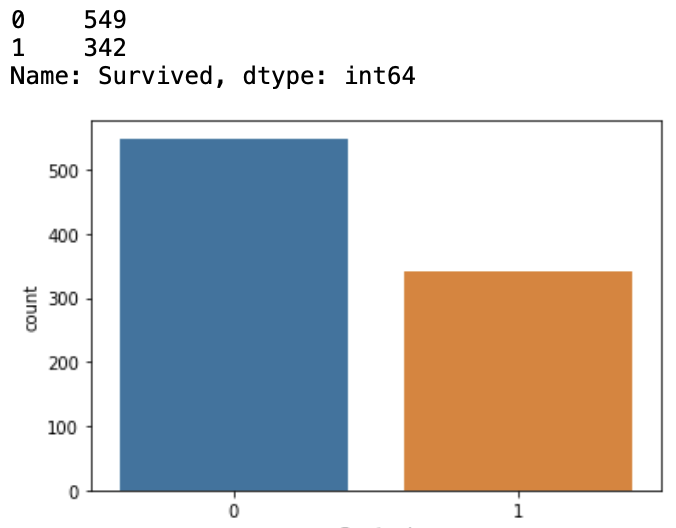
먼저 우리가 예측해야하는 '생존 여부' 가 어떻게 이루어져 있는지 보자. 생존 여부는 train 데이터에만 있고 test 에는 없다. 우리는 train 데이터에서 주어진 승객들의 정보와 그들의 생존 여부를 머신러닝에게 학습하도록 하고, test 데이터에 존재하는 승객들의 생존 여부를 맞출 것이다. 이렇게 우리가 맞춰야 하는 데이터를 타겟 변수(target variable), 혹은 종속 변수 라고 부른다. 나는 거의 타겟 변수라고 많이 부른다.
아마 이런 결과물이 나올 것이다. 0이 사망자, 1이 생존자를 의미한다. 그래프를 보면 사망자의 수가 생존자의 수보다 더 많은 것을 알 수 있다.
데이터별로 이런 타겟 변수가 한쪽의 값만 지나치게 많은 경우, 우리는 이를 'Class imbalanced problem' 이라고 부른다. 카드 사기 거래 여부, 하늘에서 운석이 떨어지는 경우를 예를 들어 보면 사기가 아닌경우, 운석이 떨어지지 않을 경우가 반대의 경우보다 그 수가 압도적으로 많다. 이때 별다른 처리 없이 머신러닝에게 데이터를 학습시킨다면, 머신러닝이 모든 데이터를 0(사망, 혹은 정상거래, 혹은 운석 안떨어짐) 이라고 예측할지도 모른다. 그리고 이 정확도를 보면, 상당히 높게 나온다. 실제로 우리가 예측하려는 데이터에도 운석이 떨어지는 날은 몇일 되지 않을 것이니까. 하지만 이 녀석은 참으로 의미없는 머신러닝 모델이 될 것이다. 실제로 우리나라 일기예보도 '365일 비 안옴' 이라고 예측하면 정확도가 75% 정도 된다고 하지만, 이것이 의미있는 예측은 아니지 않은가. 이럴때는 여러 방법들을 통해 이 불균형을 해결한 후 머신러닝 알고리즘으로 학습을 시켜야 의미있는 예측을 하는 경우가 대부분이다. 그리고 타이타닉 데이터에 있는 이 불균형정도면, 상당히 양호한 편이라고 할 수 있다.
참고로, 모든 승객을 사망 이라고 처리하고 제출해도 캐글 정확도는 약 60% 가 넘게 나온다.
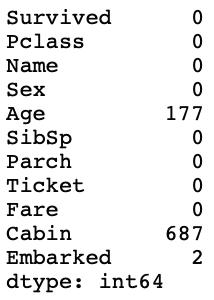
결측치는 말 그대로 측정하지 못한 값이다. 'Age' 와 'Cabin' 열에서 결측치가 특히 많이 발생한 것을 볼 수 있다. 생각해보면 결측치는 '없는 데이터' 이기 때문에, 머신러닝이 여기서 배울 수 있는것은 전혀 없다. 그리고 사용하는 머신러닝 알고리즘에 따라서 데이터에 결측치가 있는 경우 에러가 날 수도 있다. 결측치를 처리하는 방법으로는, 결측치가 있는 데이터를 지워버리는 방법도 있고, 주변값 또는 대표값으로 결측치를 채워 넣는 방법도 있다. 나는 일단 Cabin 을 먼저 지워버려야겠다.
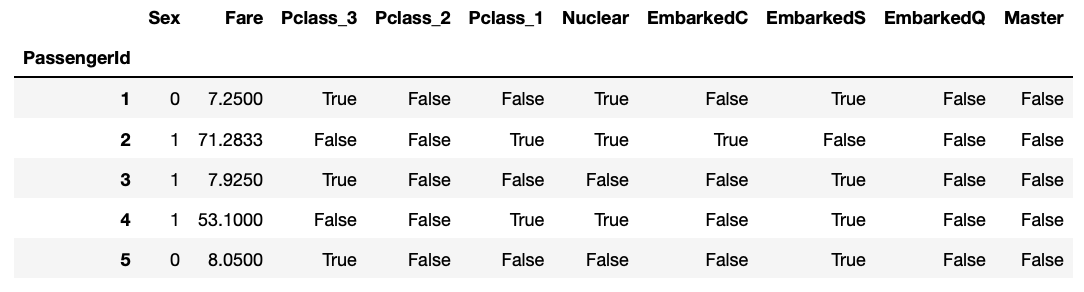
train 데이터와 test 데이터에 성별 데이터를 '인코딩' 해 준다. 머신러닝 알고리즘은 기본적으로 문자를 인식하지 못한다. 'male' 이라고 써있으면, 사람이야 바로 아 남성~ 하지만 머신러닝 알고리즘이 이걸 어떻게 알아듣겠는가? 그래서 이런 데이터를 0, 1 같은 숫자로 바꿔주는 일을 '인코딩' 이라고 한다.
첫 줄의 코드를 말로 설명하자면, "train 에서 [ train 데이터의 [성별] 이 'male' 인 사람의, '성별' 칸에는] = 0 이라고 입력해라." 정도로 해석할 수 있다. 밑에 줄들도 마찬가지.
이제 다음 칸에 "train['Sex']" 라고 쳐보면, 남성은 0, 여성은 1 로 데이터가 바뀌어있는것을 볼 수 있다.
보면, 1등석일수록 생존 확률이 높고, 3등석에는 사망률이 높아진다는 것을 알 수 있다. 역시 돈이 최고다. 아무튼 3등석보다 2등석이, 2등석보다 1등석이 생존 확률이 더 높다는 것은 머신러닝에게 좋은 정보로 작용할 것이다. 그럼 이 정보도 역시 인코딩 해주어야한다. 어? 근데 데이터가 1, 2, 3 숫자네? 아싸 개꿀~ 하려고 하는데 근데 여기서 문제가 생긴다.
기존 0과 1에서는 생기지 않았던 문제인데, 생각해보면 (1등석) + (2등석) = (3등석) 이 성립하는가?
(2등석) ^ 2 = (1등석) + (3등석) 이것도 성립하나? 개념상으로는 맞지 않다는것을 바로 알 수 있다. 이런 형태의 데이터를 '범주형 변수', 영어로 'categorical feature' 이라고 한다. 이렇게 숫자로 넣어주면 머신러닝 알고리즘은 딱 오해하기 좋다. 혹시나 수학 계산 과정이 필요한 알고리즘이라면, 위와 같은 오해를 하기 정말 좋은 상황이다. 이럴때 필요한게 바로 '원-핫 인코딩(one-hot encoding)' 이다.
이런 상황에서 원래대로 인코딩을 한다면, 데이터는 1개의 열에 모두 저장되어서 다음과 같이 표시될 것이다.
객실등급 : 1, 3, 2, 3, ....
하지만 원-핫 인코딩은 여러 개의 열을 추가한다. 이런 데이터에서 예를 들어보면,
객실 1등급 여부 : True, False, False, False, ...
객실 2등급 여부 : False, False, True, False, ...
객실 3등급 여부 : False, True, False, True, ...
이런식으로 인코딩을 진행한다. 이렇게 되면, 이 열들을 어떻게 더하고 곱하고 지지고 볶아도 중복이 나오지 않는다! 하지만 이 원핫 인코딩의 치명적인 단점은, 처리해야할 변수의 갯수가 아주아주 많아진다는 것이다. (그럴 일은 없겠지만) 만약에 객실이 60개 등급으로 이루어졌다면.... 총 60개의 변수가 생긴다. 이는 Tree 기반의 머신러닝 알고리즘에서 그닥 좋은 영향은 주지 못한다. 때에 따라서 원핫 인코딩할 변수가 너무 많다면, 그냥 1, 2, 3, ... 으로 인코딩 하기도 한다. (머신러닝 라이브러리 sklearn 에서는 이를 'LabelEncoder' 로 구현해두었다.) 상황에 따라 적절한 대처가 필요하다.
코드를 말로 해석해보자면 "train 데이터에 있는 ['Pclass_3'] 이라는 열에 (없으면 만들고) train 데이터의 ['Pclass'] 열의 값이 3인 애들은 True, 아니면 False 로 입력해줘라" 라는 뜻이다. 밑에 줄도 마찬가지로 해석할 수 있다. 이렇게 되면 위에서 언급한 대로 원-핫 인코딩을 할 수 있다. 원-핫 인코딩을 완료했으니, 더이상 필요가 없어진 원래의 'Pclass' 열은 삭제하도록 하자.
못보던게 하나가 등장했는데 'fit_reg' 이다. 이 lmplot(엘 엠 플랏) 은 이런 점찍혀있는 그래프와, 점들을 대표하는 하나의 직선이 있는 그래프인데, 나는 점만 보고 싶어서 선을 없앴다. 이 선을 없애는 명령이 'fit_reg=False' 이다. 선 궁금하면 한번 'fit_reg=True' 라고 해봐도 된다.여기서만 볼때는 딱히 유의미하다고 판단하기가 어렵다. 그래프를 확대해보자.
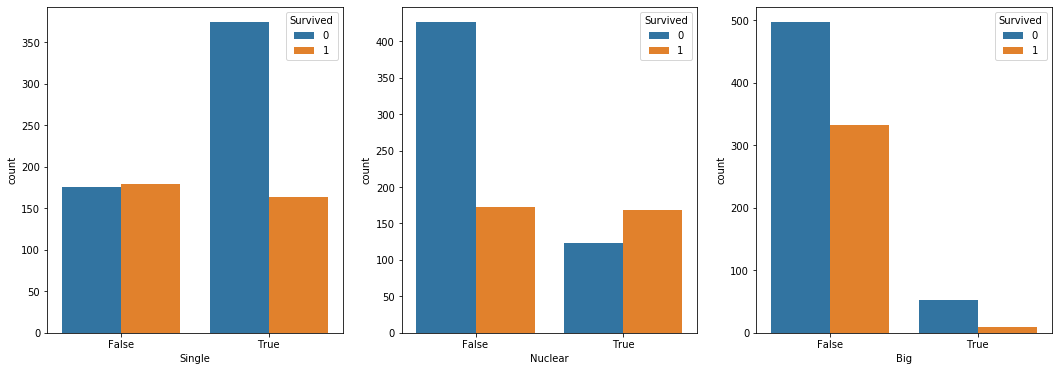
train, test 각 데이터의 SibSp, Parch 를 더하고 1을 더해서 'FamilySize' 라는 이름의 변수를 추가로 만들었다. 여기서 보면 알 수 있는 사실은, FamilySize 가 2 ~ 4 인 경우에는 생존률이 더 높았다는 사실을 알 수 있다. 핵가족의 전형적인 인원수이다. 이들은 빠르게 뭉쳐서 다같이 빠른 판단을 해서 생존률이 높은 것일까? 가설의 진실은 알 수 없지만, 이들 데이터가 가진 사실은 알 수 있다. 이들은 생존률이 높았다는 것이다.
영어 이름에는 성별 정보가 포함되어 있다. 이는 이름을 가지고도 생존 여부를 어느정도 예측할 수 있다고 볼 수도 있다. 또한 한 가족은 한 성씨(Last Name)를 따르니까, 위에서 말한 FamilySize를 남겨놓고 (LastName + FamilySize) 를 만들어서 일종의 FamilyID 를 만들 수도 있을 것이다. 예를들면, Johnson5 이런식이다. Johnson 성을 가진 5명 일행. 아마 일행중 한명이 사망했다면, 다른 구성원들도 사망했을지도 모른다. 이런식의 가설 세우기도 충분히 가능하지만, 난 귀찮으니 안하겠다. 해보고싶으면 한번 해봐도 좋을 것이다. 절대 내가 귀찮아서 그런게 아니다.
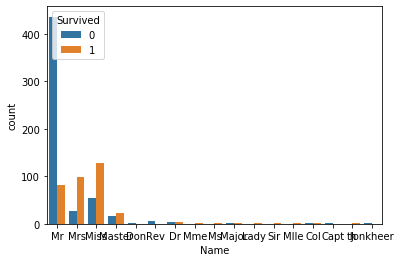
Mr 은 남자의 호칭이다. Ms, Mrs 는 여자의 호칭이다. 이는 위에서 보았던 성별 차이에 따른 생존률의 차이와 일맥상통한다. 하지만 여기서 특이한점은 'Master' 호칭의 사람들도 생존 숫자가 더 많았다는 것이다. 나중에 알게 되었는데, 이 'Master' 가 옛날 영어에서 어린 남자들을 지칭하는 호칭이란다. 카더라. 아무튼 우리가 알 수 있는 정보는, Master 호칭을 가진 남자들은 생존률이 더 높다는 것을 의미한다.
train과 test 에서 'Master' 여부 True or False 를 구분하는 변수를 만들고, 나머지 이름 데이터를 삭제한다.
여기서 굳이 Ms, Mrs 를 따로 같이 뽑아주지 않았냐고 물어보신다면, 이미 얘네들은 여자이기 때문에, 머신러닝 알고리즘은 얘네들을 살 가능성이 높다고 판단할 것이라고 생각했다. 하지만 이 머신러닝은 남자들은 대부분 죽었다고 판단할 것이다. 우리가 데이터 분석을 하면서 정확도를 올릴 수 있는 방법은, 머신러닝이 죽었다고 판단할 남자들 중 살았을 확률이 높은 부분, 살았다고 판단했을 여자들이 죽었을 확률이 높은 부분을 찾아서 변수로 추가해주어야 정확도를 높일 수 있다. 여기서 Ms, Mrs 를 추가한다는것은 아무 의미 없이 변수만 늘리는 행위일 뿐이다. 위에서도 언급했듯이, 변수가 많아지면 결과에 좋은 영향을 끼치지 않을 가능성이 꽤 높다.
티켓은 티켓 번호를 의미한다. 그냥지우자. 귀찮다.
4. 머신러닝 모델 생성 및 학습
이제 머신러닝 모델을 만들고 학습시키고 데이터를 예측시키면 모든 과정이 끝이 난다.
머신러닝 모델은 sklearn(scikit-learn) 의 DecisionTree를 사용할 것이다.
우리가 맞춰야 할 '생존여부' 를 Ytrain 이라는 이름에 변수에 저장했고, 승객 정보를 담고있는 나머지 데이터 (train 데이터에서 Survived 를 제외한 나머지 열) 들을 Xtrain, Xtest 라는 변수에 담았다.
다시 말하지만, 이 Xtrain 안에 있는 승객 정보를 가지고 Ytrain (생존여부) 를 학습한다. 그리고 머신러닝이 본 적 없는 데이터인 Xtest 에 대해서도 Ypred(예상 생존여부) 를 예측하는 것이 우리의 목표이다.
저 print 문이 실행된다면 아마 이렇게 출력될 것이다 :
(891, 10) (891,) (418, 10)
이때 확인해야 할 것은, Xtrain 과 Ytrain의 행 수가 일치하는지, Xtrain 과 Xtest 의 열 수가 일치하는지를 확인해야 한다. 이게 안맞으면 안돌아간다. 위에 데이터 분석 과정에서 무언가 빼먹었다는 뜻이다. '.head()' 라는 메소드는 해당 데이터프레임 (여기서는 Xtrain) 의 첫 5개 줄(행) 을 보여준다.
데이터 분석하고 정리한 머신러닝에 들어갈 최종 결과물
model=DecisionTreeClassifier(max_depth=8, random_state=18)
# random_state is an arbitrary number.
model.fit(Xtrain, Ytrain)
predictions=model.predict(Xtest)
submission['Survived']=predictions
submission.to_csv('Result.csv')
submission.head()
model 은 머신러닝 모델인 DecisionTreeClassifier을 저장했다. 여기서는 깊이 8을 설정했다.
model.fit(Xtrain, Ytrain) : Xtrain 으로 Ytrain 을 학습해라.
model.predict(Xtest) : .fit() 이 끝난 이후에 실행할 수 있다. Xtest를 예측해라.
그러면 이제 submission 파일의 'Survived' 에다가 예측한 결과를 넣어서 '.to_csv' 로 저장할 수 있다. 저장된 파일은 주피터 노트북 파일과 같은 경로에 저장된다.