VAE(Variational AutoEncoder)와 AE(AutoEncoder)는 구조상으로는 비슷하지만 의미적인(?) 측면에서 약간의 차이가 있다. 일반적인 오토인코더는 입력된 데이터를 저차원으로 최대한 잘 압축하는 방법에 그 초점이 맞춰져 있다면, VAE는 입력 데이터를 저차원으로 잘 압축시키고, 그 특성에 따라 새로운 데이터를 잘 생성해 내는 것에 초점이 더 맞춰져 있다.
AE의 문제라고 한다면, AE의 결과물은 잠재 공간의 한 포인트가 되므로, 잠재 공간이 연속적으로 만들어지지 않는다는 것이다. 만약 인코딩된 결과물 (2, -2)가 숫자 4의 이미지로 완벽하게 디코딩이 되더라도, 포인트 (2.1, -2.1) 이 4와 비슷한 이미지로 디코딩될 것이라는 보장은 그 어디에도 없다. 그럴 필요도 없고. 잠재 공간이 2차원이라면 이런 문제는 상당히 덜해지지만, 잠재 공간의 차원이 늘어날수록 이 문제는 더더욱 심해지게 된다.
VAE는 여기서 출발하는데, AE와 가장 직접적인 차이점은 VAE는 이미지를 잠재 공간의 한 점으로 직접 매핑시키는 것이 아니라, (그 포인트의 주변까지도 약간씩 포함 할 수 있도록) 그 점 주변의 다변수 정규 분포 함수에 매핑한다는 것이다. 이렇게 되면 인코딩 결과물 (2,-2)가 숫자 4의 이미지로 정확히 디코딩될 수 있다면, (2.1, -2.1) 역시 점 (2, -2)와 상당히 비슷한 위치에 있기 때문에 숫자 4와 상당히 비슷한 디코딩 결과를 낸다고 추론할 수 있다.
요약하자면, VAE의 인코더는 입력된 이미지를 잠재 공간의 (한 포인트를 중심으로 하는) 다변수 정규 분포로 만들게 된다. 이미지 1을 일반적인 오토인코더로 인코딩한 결과가 (1, 1)이라면, VAE는 이 이미지 1을 (1, 1)을 중심으로 하는 (다변수) 정규 분포 함수를 만든다. 따라서 디코더는 이 (1, 1) 근처의 점들은 정규분포에 따라서 이미지 1 일 '확률' 이 높다고 판단하고, 이미지 1과 비슷한 형태를 띠도록 디코딩을 학습할 가능성이 높다. 하지만 점 (1, 1)과 멀리 떨어진 점 (100, 100)에 대해서는 정규분포에 따라서 이미지 1일 '확률' 이 높지 않다고 판단하고, 디코딩 결과물이 이미지 1과 비슷해지지 않도록 학습할 것이다.
정규 분포를 정의하려면 두가지의 변수가 필요한데, 바로 평균과 분산이다. 따라서, 인코더는 입력된 이미지에 대하여, 평균과 분산, 두 가지 아웃풋을 낸다. 여기에다가 'epsilon' 항을 추가해서 정규 분포를 만드는데, epsilon 은 표준 정규분포에서 랜덤하게 샘플링 한 값이다. 이 epsilon의 역할은 '인코더가 만들어낸 다차원 정규분포에서 얼마나 떨어진 곳을 디코딩 시작 포인트로 잡을까'를 결정한다. 이 값이 결정되면 디코더는 인코더의 정확한 결과물 (인코더가 만들어낸 정규분포의 중심점) 이 아닌, 그 포인트 주변의 약간 떨어진 점으로부터 디코딩을 시작해야 하므로 한 번도 본 적 없는 포인트에 대해서 디코딩을 진행해야 한다. 하지만 그 시작점이 인코더의 정확한 결과물과 아주 크게 다르지는 않기 때문에 (epsilon도 정규분포를 따르므로, epsilon 값이 비정상적으로 큰 값이 나올 확률 매우 적다) 원본과 비슷한 결과물을 내야만 Loss 가 커지지 않을 것이다.
책을 천천히 다시 읽어보고 이해한 결과를 정리했다. 머릿속으로 3차원을 넘어가는 그림이 그려지지는 않아서, (그게 됐다면 난 이런거 쓰고 있지 않았겠지?) 그리고 고등학교 수포자 이과생인 전력이 있는 나이기 때문에 정확한 수학적 이해나, 확률론(?)적으로 깔끔하게 설명할 수는 없지만, 굳이 이해를 하자면 이렇게 될 것이다.
VAE에서는 잠재 공간의 차원 사이에는 어떤 상관관계가 없다고 가정하고 시작한다. 다시 말하면, 잠재 공간에서의 차원간의 상관계수는 0이고, 공분산 행렬은 계산할 필요가 없으며, 그러므로 인코더가 입력을 평균, 분산으로만 매핑할 수 있게끔 가정을 한다.
VAE를 만드는 일은 생각보다 간단한데, 일반적인 오토인코더를 만든 후, 인코더가 정규분포를 만들 수 있도록 수정, 손실 함수가 정규분포를 인식할 수 있도록 수정해주면 된다. 단어가 조금 이상하다.
대충 코드를 보자면 다음과 같다.
1. VAE 만들기
import pandas as pd
import numpy as np
import keras
from keras.layers import Input, Conv2D, Flatten, Dense, Conv2DTranspose, Reshape, Activation, LeakyReLU, Dropout, BatchNormalization, MaxPooling2D, Lambda
from keras.models import Model
from keras import backend as K
from keras.optimizers import Adam
from keras.utils import to_categorical
from sklearn.metrics import mean_squared_error as mse
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns패키지 import 하고,
(Xtrain, Ytrain), (Xtest, Ytest) = keras.datasets.mnist.load_data()
Xtrain=Xtrain/255
Xtest=Xtest/255
Xtrain=Xtrain.reshape(len(Xtrain), 28, 28, 1)
Xtest=Xtest.reshape(len(Xtest), 28, 28, 1)
Ytrain=to_categorical(Ytrain)
Ytest=to_categorical(Ytest)데이터 불러와서 저장, 전처리
1.1. 인코더 만들기
#Encoder
encoder_input=Input(shape=(28,28,1))
x=Conv2D(filters=32, kernel_size=3, strides=1, padding='same')(encoder_input)
x=LeakyReLU()(x)
x=Conv2D(filters=64, kernel_size=3, strides=2, padding='same')(x)
x=LeakyReLU()(x)
x=Conv2D(filters=64, kernel_size=3, strides=2, padding='same')(x)
x=LeakyReLU()(x)
x=Conv2D(filters=64, kernel_size=3, strides=1, padding='same')(x)
x=LeakyReLU()(x)
shape_before_flatten=K.int_shape(x)[1:]
x=Flatten()(x)
#############################################################################
mu=Dense(units=2)(x)
log_var=Dense(units=2)(x)
def sampling(args):
mu, log_var = args
epsilon = K.random_normal(shape=K.shape(mu), mean=0, stddev=1)
return mu + K.exp(log_var / 2) * epsilon
encoder_output=Lambda(sampling)([mu, log_var])
model_encoder = Model(encoder_input, encoder_output)
############################################################################
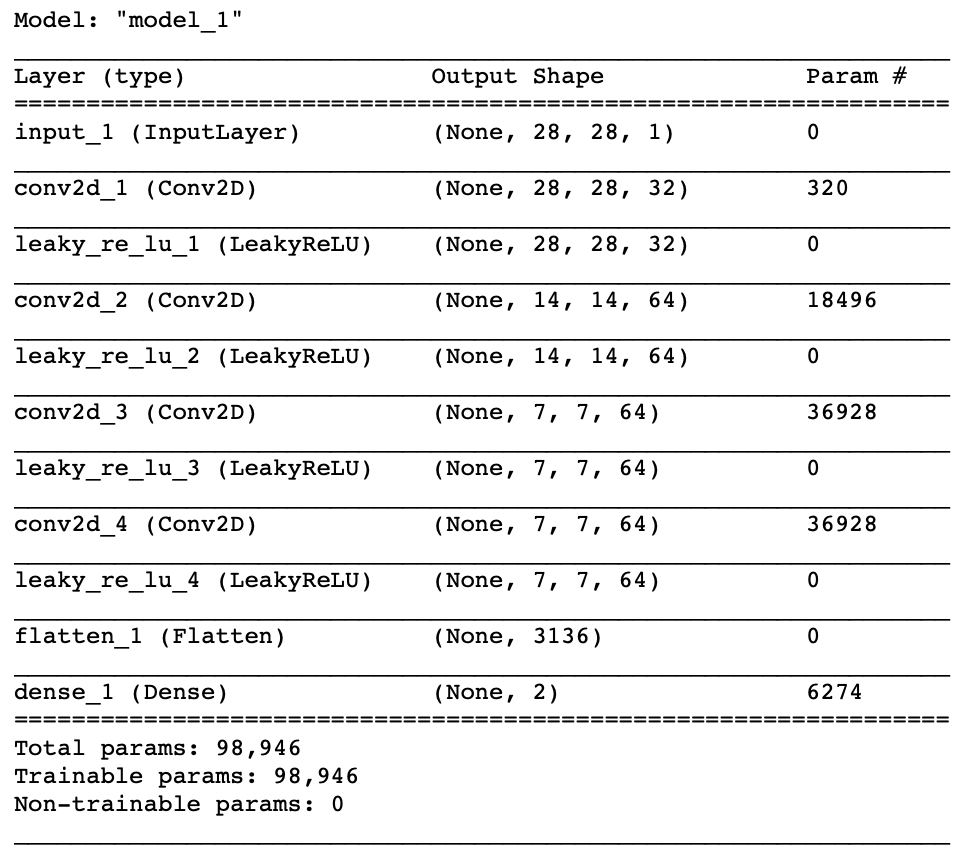
print(model_encoder.summary())코드를 자세히 뜯어보면 윗부분은 똑같다. 복사해서 갖다썼으니까 똑같다.
다만 아랫부분 ##### 으로 표시한 부분이 약간 다른데, (이래서 함수형 API 쓰라고 하는구나) 몇 번의 Convolution Layer를 지난 데이터는 Flatten 이후에 두 경로로 가게 된다.
한쪽은 mu(뮤, 평균)를 정하고, 다른 한쪽은 log_var(로그 분산)을 정한다. (분산은 항상 양수이므로 로그를 씌워도 괜찮다)
아래 공식으로 표준과 표준편차가 정의된 정규분포에서 특정 포인트를 샘플링할 수 있다. (표준편차는 분산의 양의 제곱근이므로 분산도 오케이다.) 공식의 epsilon은 표준 정규분포(평균=0, 표준편차=1 인 정규분포)를 따르는 임의의 점이다.

그리고 그 아래에 있는 'sampling' 함수는 위에서 만들어진 평균과, (로그) 분산으로 정의된 정규 분포(분포 A라고 하자)에서 epsilon값을 추가해 분포 A에서 한 포인트를 샘플링한다.
인코더의 아웃풋 층은 뮤, 로그분산 두 가지를 입력으로 묶어서 입력받은 후, 샘플링 함수를 실행해서 샘플링된 포인트를 반환한다.
인코더를 이렇게 변경해주고, 디코더를 똑같이 연결해주면 VAE 설계의 첫 번째 단계가 끝난다.
#Decoder
decoder_input=Input(shape=(2,))
x=Dense(units=np.prod(shape_before_flatten))(decoder_input)
x=Reshape(shape_before_flatten)(x)
x=Conv2DTranspose(filters=64, kernel_size=3, strides=1, padding='same')(x)
x=LeakyReLU()(x)
x=Conv2DTranspose(filters=64, kernel_size=3, strides=2, padding='same')(x)
x=LeakyReLU()(x)
x=Conv2DTranspose(filters=32, kernel_size=3, strides=2, padding='same')(x)
x=LeakyReLU()(x)
x=Conv2DTranspose(filters=1, kernel_size=3, strides=1, padding='same')(x)
x=Activation('sigmoid')(x)
decoder_output=x
model_decoder=Model(decoder_input, decoder_output)
print(model_decoder.summary())
#Connect Two Models
model_input = encoder_input
model_output = model_decoder(encoder_output)
AutoEncoder=Model(model_input, model_output)
1.2. 손실 함수 수정
인코더가 정규분포(에서 샘플링한 한 포인트) 를 내뱉도록 설계가 완료되었으면, 이제 손실 함수를 수정하면 된다. 기존의 AE에서는 픽셀 별로 값을 비교해서 구한 mean squared error 만 사용했다면, 여기서는 KL 발산(Kullback - Leibler Divergence, 쿨백 - 라이블러 발산)을 추가로 사용한다.
KL발산에 대한 설명을 간단히 요약하자면, 한 확률분포가 다른 확률분포와 얼마나 다른지를 측정하는 방법이라고 할 수 있다. VAE가 생성해낸 평균 mu, 분산 log_var인 정규분포가 표준 정규분포와 얼마나 다른지를 측정해야 하기 때문에, 손실 함수(loss_function) 에 KL발산 항을 추가한다. 이때 KL 발산을 계산하려면 다음과 같이 하면 된다.
kl_loss = -0.5 * sum( 1 + log_var - mu^2 - exp(log_var)
모든 차원에서 잠재공간상의 정규분포가 mu = 0, log_var = 0 일 때 kl_loss는 최소가 된다. 이렇게 추가한 KL 발산 항은 네트워크가 샘플을 표준 정규분포에서 크게 벗어나게 인코딩할 때 큰 페널티를 가하게 된다.
optimizer=Adam(lr=0.0005)
r_loss_factor=1000 # This is a Hyperparameter
def vae_r_loss(y_true, y_pred): ## MSE
r_loss = K.mean(K.square(y_true-y_pred), axis=[1,2,3])
return r_loss_factor * r_loss
def vae_kl_loss(y_true, y_pred): ## KL-Divergence
kl_loss= -0.5 * K.sum(1+log_var - K.square(mu) - K.exp(log_var), axis=1)
return kl_loss
def vae_loss(y_true, y_pred):
r_loss=vae_r_loss(y_true, y_pred) #Loss of Decoder
kl_loss = vae_kl_loss(y_true, y_pred) #Loss of Encoder
return r_loss + kl_loss #Sum of these two
AutoEncoder.compile(optimizer=optimizer, loss= vae_loss, metrics=[vae_r_loss, vae_kl_loss])새로 만들 VAE에서의 loss function은 여기서 정의한 'vae_loss' 함수를 이용한다. vae_loss 는 기존의 MSE 손실 함수와 KL 발산의 합으로 계산된다. MSE 손실 함수는 (원본 이미지 픽셀과 생성 이미지 픽셀을 비교하여) 디코더가 원본과 비슷한 이미지를 생성해내지 못할 시 더 큰 페널티를 주고, KL발산은 인코더가 표준 정규분포와 많이 다른 분포로 데이터를 인코딩할수록 더 큰 페널티를 주게 된다.
여기서는 또 'r_loss_factor' 이라는 것이 추가되었는데, 이는 mse에 곱해주는 가중치로 KL 발산 손실과 균형을 맞추는 용도이다. 이 'r_loss_factor'는 하이퍼파라미터로, VAE를 훈련할 때 튜닝을 잘해주어야 한다. 이 가중치가 너무 크면, KL발산(인코더의 Loss)이 역할을 제대로 못하게 되고, 너무 작으면 (디코더의 Loss에 대한 비중이 적어지기때문에) 생성된 이미지의 퀄리티가 좋지 않을 것이다.
2. VAE 학습시키기
for i in range(10):
print(f"Trial {i}...")
AutoEncoder.fit(Xtrain, Xtrain, batch_size=32, shuffle=True, epochs=20)
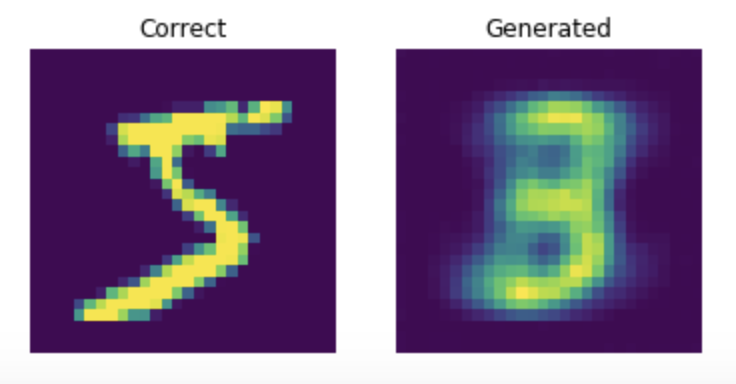
result=AutoEncoder.predict(Xtrain)
random=np.random.randint(0, len(Xtrain))
fig = plt.figure()
rows = 1
cols = 2
img1 = Xtrain[random].reshape(28,28)
img2 = result[random].reshape(28,28)
ax1 = fig.add_subplot(rows, cols, 1)
ax1.imshow(img1)
ax1.set_title('Correct')
ax1.axis("off")
ax2 = fig.add_subplot(rows, cols, 2)
ax2.imshow(img2)
ax2.set_title('Generated')
ax2.axis("off")
plt.show()그래프를 띄우는 코드를 똑같이 복사해서 가져왔다. 20에포크당 생성 이미지를 한 번씩 띄우는 과정을 10회 반복하여 총 200 에포크만큼의 반복 학습을 진행한다.
다음 장으로 넘어가기 전에 이 r_loss_factor의 값을 조금씩 만져보며 수정해보고, 손실이 수렴해가는 과정을 좀 지켜보고, 결과물도 이미지로 꺼내서 한번 봐야겠다. 이 다음에는 VAE로 MNIST 데이터 말고, 얼굴 이미지를 생성하는 것을 해봐야겠다.