VAE로 이미지의 특성을 뽑아서, 이미지에 변형을 가하며 새로운 이미지를 생성할 수 있다. 웃지 않는 사진에 웃음을 추가한다던지, 선글라스를 씌운다던지 할 수 있다는 것을 할 수 있다.
또 다른 생성 모델은 'GAN'이다. Generative Adversarial Network, (생성적 적대 신경망)이라고 하는데, 처음 논문이 나왔을 때 아주 혁신적인 아이디어로 세간의 이목을 집중시켰다고 한다.
GAN은 생성자와 판별자, 두 개의 신경망으로 이루어진 신경망이다. 생성자와 판별자는 서로 경쟁하는 구도를 가지는데, 각각의 역할이 존재한다. 판별자는 이미지가 Input으로 들어오면 이 이미지가 원래 있던 이미지인지(target = 1), 아니면 새로 생성된 이미지인지 (target = 0)을 예측하는 역할을 한다. 생성자는 랜덤한 노이즈가 주어지면, 이를 이용해서 이미지를 생성하는 역할을 한다. 이렇게 생성된 이미지는 판별자에게 주어져서, 판별자는 이 이미지의 진위여부를 판단하게 된다. 이 두 모델은 서로 계속해서 학습하며 판별자는 더더욱 생성된 이미지를 잘 구분할 수 있게 되고, 생성자는 더더욱 판별자가 잘 구분할 수 없는 '진짜 같은' 이미지를 만들어내게 된다.
지금 들어도 예측 모델링만 하던 내가 이 아이디어를 듣고 와 정말 신기하다. 여기서 이렇게 할 수도 있구나 라는 생각을 했었다. 이번에는 camel numpy 파일을 이용해 직접 GAN을 만들어보고, 새로운 데이터를 생성해보자.
camel numpy 데이터는 구글의 'Quick, Draw!' 데이터셋의 일부이다. 이 데이터셋은 온라인 게임으로부터 수집되었는데, 유저가 그림을 그린 것을 신경망이 맞추는 게임이다. 이 결과물이 주제별로 묶어져 .npy 파일로 저장되어있다.
여기서 다운로드 받을 수 있다.
GAN의 원본 논문에서는 Convolution층 대신에 Fully-Connected 층을 사용했다고 한다. 하지만 그 이후로 합성곱 층이 판별자의 예측 성능을 크게 높여 준다고 밝혀진 이후로, 간단한 GAN 모델들도 합성곱 층을 사용하고 있다. 이러한 모델은 사실 DCGAN (Deep Convolution GAN)이라고 부르는 게 정확하지만, 합성곱 층이 너무나 많이 쓰이고 있어서 GAN이라고 해도 DCGAN의 의미를 포함하고 있다고 한다.
1. 패키지 및 데이터 로드
import pandas as pd
import numpy as np
import keras
import keras.backend as K
from keras.layers import Conv2D, Activation, Dropout, Flatten, Dense, BatchNormalization, Reshape, UpSampling2D, Input
from keras.models import Model
from keras.optimizers import RMSprop
from keras.preprocessing.image import array_to_img
import warnings ; warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
from tqdm import tqdm패키지를 로드하고,
Xtrain = np.load('full-numpy_bitmap-camel.npy')
Xtrain = np.reshape(Xtrain, (len(Xtrain), 28, 28, 1))
Xtrain = Xtrain / 255MNIST 데이터셋처럼 0~255의 픽셀 강도가 numpy로 저장되어있다.
책과 다른 게시물에서는 -1 ~ 1로 값을 맞춰주는데, 그냥 귀찮아서 0 ~ 1 로 맞추어주었다. 그렇다면, 마지막 단계, 생성자의 이미지 출력물을 0~1 사이로 맞춰주는 sigmoid를 사용해야겠다.
2. 판별자 만들기
disc_input = Input(shape=(28, 28, 1))
x = Conv2D(filters=64, kernel_size=5, strides=2, padding='same')(disc_input)
x = Activation('relu')(x)
x = Dropout(rate=0.4)(x)
x = Conv2D(filters = 64, kernel_size=5, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = Dropout(rate=0.4)(x)
x = Conv2D(filters=128, kernel_size=5, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = Dropout(rate=0.4)(x)
x = Conv2D(filters=128, kernel_size=5, strides=1, padding='same')(x)
x = Activation('relu')(x)
x = Dropout(rate=0.4)(x)
x = Flatten()(x)
disc_output = Dense(units=1, activation='sigmoid', kernel_initializer='he_normal')(x)
discriminator = Model(disc_input, disc_output)
discriminator.summary()discriminator의 앞 4자 disc를 사용해서 판별자를 만들었다.
판별자를 만드는 코드를 간단히 설명하자면, 단순히 4번의 Convolution을 거쳐서, 해당 이미지가 참인지 거짓인지만을 판별한다. 마지막의 sigmoid 함수를 지나서 이 이미지가 진짜일 확률을 출력하게 된다.

3. 생성자 만들기
gen_dense_size=(7, 7, 64)
gen_input = Input(shape = (100, ))
x = Dense(units=np.prod(gen_dense_size))(gen_input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Reshape(gen_dense_size)(x)
x = UpSampling2D()(x)
x = Conv2D(filters=128, kernel_size=5, padding='same', strides=1)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
x = UpSampling2D()(x)
x = Conv2D(filters = 64, kernel_size=5, padding='same', strides=1)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
x = Conv2D(filters=64, kernel_size=5, padding='same', strides=1)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation('relu')(x)
x = Conv2D(filters=1, kernel_size=5, padding='same', strides=1)(x)
gen_output = Activation('sigmoid')(x)
generator = Model(gen_input, gen_output)
generator.summary()gen_dense_size에 shape를 하나 주었는데, 이 값은 랜덤 노이즈로부터 처음 생성할 Raw 이미지의 사이즈이다. 이 Raw 이미지는 몇 번의 UpSampling2D와 Convolution2D 레이어를 거쳐서 원본 이미지와 같은 shape를 가진 이미지로 바뀐다. 여기서 Conv2DTranspose (전치 합성곱) 층 대신에 UpSampling2D를 사용했는데, 이 둘은 픽셀을 다루는 원리가 약간씩 다르다. Conv2D 같은 경우에는 합성곱 연산을 진행하기 전에 픽셀 사이에 0을 추가하는 반면, UpSampling2D는 각 행렬을 단순히 반복하여 이미지 사이즈를 두배로 만든다. Conv2DTranspose를 사용하면 이미지에 계단 모양이나 체크무늬 패턴을 만들어서 이미지 품질을 저하시킬 수 있다고 알려져 있지만, 뛰어난 GAN 논문에서 여전히 많이 사용된다. 따라서 두 방식을 모두 시도해보고 더 좋은 결과를 출력하는 방법을 사용하는 것이 바람직하다.
생성자의 코드를 확인해보자면, 100차원의 랜덤 노이즈를 7 * 7 * 64 사이즈의 이미지로 만들고, 이를 키우면서 진행된다. 이전 레이어에서 받은 이미지를 UpSampling 하여 두 배로 크기를 늘리고, Convolution을 진행하고, 다시 UpSampling 하고, Convolution 하고를 반복한다. 마지막에는 sigmoid 함수를 적용시켜서 출력 결과물이 원본 데이터와 같은 스케일 안에 있게끔 만든다. 내가 시작할 때 Xtrain 데이터를 0 ~ 1 사이의 값으로 만들었기 때문에 다른 코드들처럼 tanh를 사용하지 않고 sigmoid 함수를 사용하는 것이 맞다고 판단했다.

4. 모델 컴파일
discriminator.compile(optimizer=RMSprop(lr=0.0008), loss='binary_crossentropy', metrics=['accuracy'])판별자를 컴파일해준다. 이미지의 진위를 판단하는 Binary 문제이므로 loss function은 binary_crossentropy를 사용하고, metrics 에는 정확도를 사용하여 모니터링한다.
discriminator.trainable = False
model_input = Input(shape=(100, ))
model_output = discriminator(generator(model_input))
model = Model(model_input, model_output)
model.compile(optimizer=RMSprop(lr=0.0004), loss='binary_crossentropy', metrics=['accuracy'])이제 생성자를 컴파일해줘야 하는데, 생성자에서 생성한 이미지를 판별자에 넣고 그 이미지의 참 거짓을 판별하도록 하는 모델을 만들어서 컴파일을 한다. 어차피 이렇게 모델을 새로 컴파일해도, 그 안에 있는 생성자도 같이 컴파일되므로, 추후에 생성자만 이용해서 이미지를 생성하는 것이 가능하다.
일반적으로 판별자가 더 강력해야, 생성자가 판별자의 학습을 따라가면서 점점 좋은 결과물을 생산해내기 때문에, 판별자의 learning rate의 절반으로 생성자를 컴파일해준다.
이때 헷갈리는 것 중 하나가, 'discriminator.trainable = False'인데, 이 코드가 있어야 생성자에서 생성된 데이터를 학습하는 과정에서 판별자의 가중치가 업데이트되지 않는다. 이 trainable 속성은 모델이 컴파일할 때 작동하는데, 설명하자면 아래와 같다.
1. 판별자를 컴파일할 때는 trainable=True로 되어있는 상태로 컴파일 진행.
2. 판별자를 컴파일한 이후 trainable=False로 설정해주어도 이미 컴파일된 판별자에는 적용되지 않음.
3. 새로 판별자를 컴파일한 모델을 만드는데, 이때는 아까 trainable=False로 해두었기 때문에 판별자의 가중치가 업데이트되지 않음. 하지만 기존에 판별자만 컴파일할 때 trainable=True 이므로, 판별자만 학습을 진행할 때는 가중치가 업데이트됨.
정도로 이해하면 된다. trainable 속성이 컴파일 시에 적용되는 건지를 모르고 있다가 이제야 알게 되었다.
요약하자면, 새로 만든 model 객체는, 100차원의 데이터를 받아서 생성자에 입력하고, 생성자가 출력한 이미지를 판별자에 넣어서 이 이미지의 진위여부를 판별자로 하여금 예측하도록 한다.
5. GAN 모델 훈련
GAN은 다른 것보다 훈련하는 아이디어가 핵심이다.
1. 원본 데이터에서 랜덤하게 데이터를 추출하여 판별자 학습. (target = 1)
2. 학습되지 않은 생성자가 랜덤 노이즈를 이용해서 생성한 이미지로 판별자 학습 (target = 0)
을 해주면서 판별자는 원본 이미지와 생성된 이미지의 차이를 구분하게 된다. 생성자가 잘 훈련이 되려면, 이 이미지가 판별자의 input으로 주어졌을 때, 판별자가 1을 뱉어내기 시작한다면 학습이 잘 진행되고 있다는 의미이다.
def train_discriminator(x_train, batch_size):
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
idx = np.random.randint(0, len(Xtrain), batch_size)
true_imgs = Xtrain[idx]
discriminator.fit(true_imgs, valid, verbose=0)
noise = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(noise)
discriminator.fit(gen_imgs, fake, verbose=0)
def train_generator(batch_size):
valid = np.ones((batch_size, 1))
noise = np.random.normal(0, 1, (batch_size, 100))
model.fit(noise, valid, verbose=1)코드를 요약하자면, 판별자 학습 함수, 생성자 학습 함수를 만든다.
판별자 학습 함수에서는, 원본 데이터에서 배치 사이즈만큼 랜덤하게 뽑아와서 타겟 1 (진짜)를 주고 학습을 시키고, 생성자가 만들어낸 이미지에다가는 타겟 0 (가짜)를 주고 학습을 시킨다. 생성자를 훈련할 때 이 생성자는 점점 진짜 같은 이미지를 생성하게 되므로 이렇게 학습을 반복해주면 판별자는 원본 이미지와 만들어진 이미지를 더욱 잘 구분할 수 있게 된다.
학습은 다음과 같은 과정의 반복으로 이루어진다.
1. 판별자는 원본 이미지를 가져와서 1로, 생성된 이미지를 0으로 학습한다.
2. 생성자는 랜덤 노이즈로부터 이미지를 1이라고 지정하고 학습하며, 가중치를 업데이트한다.
3. 판별자는 다시 원본 이미지와 (업데이트된) 생성자가 생성한 이미지를 가지고 다시 원본 이미지와 생성된 이미지를 각각 1, 0으로 학습한다.
판별자는 원본과 생성 이미지를 정확히 구분하면 loss 가 낮아진다. 반면 생성자의 목표는 판별자의 loss를 높이는(원본과 생성이미지를 구분하지 못하도록)것이 목표이다. model 객체에서 표시되는 loss는, 생성된 이미지에 대한 판별자의 loss를 의미하므로, 학습이 잘 진행될수록 이 결과는 점점 높아질 것이다.
배치 사이즈 64로, 2000 에포크만큼 학습을 진행해보았다.
for epoch in tqdm(range(2000)):
train_discriminator(Xtrain, 64)
train_generator(64)

학습이 진행될수록 'model' 객체에 표시되는 loss 가 점차적으로 증가하고 있다. 다시 한번 요약하자면, 여기에 표시되는 loss는 새로 생성된 이미지에 대한 판별자의 loss이기 때문에, 점점 증가해야 한다.
6. 결과물 확인
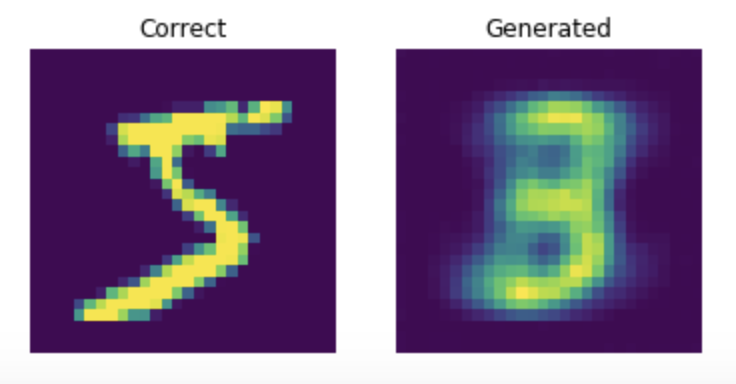
original=array_to_img(Xtrain[0])
plt.imshow(original, cmap='gray')
random_noise=np.random.normal(0, 1, (1, 100))
gen_result=generator.predict(random_noise)
gen_img=array_to_img(gen_result[0])
plt.imshow(gen_img, cmap='gray')
생성자가 어느 정도 학습이 되었다. 랜덤한 노이즈를 입력받으며 출발해서, 원본과 상당히 비슷한 낙타 모양으로 만들어냈다.
보고 있는 책에서는 6000 에포크만큼 학습을 진행하였는데, 나도 해봐야겠다.