1년만에 큰 대회에서 한번 더 수상을 하게 되었습니다. 국가정보원, 국가보안기술연구소에서 주최하고, Dacon 에서 운영한 HAICon2021, 산업제어시스템 보안위협 탐지 AI 경진대회에서 4위와 특별상을 수상하게 되었습니다.
데이콘 대회 바로가기:
HAICon2021 산업제어시스템 보안위협 탐지 AI 경진대회 - DACON
좋아요는 1분 내에 한 번만 클릭 할 수 있습니다.
dacon.io
시드 고정과 Threshold 설정하는 부분의 코드가 좀 부족해서 점수 재현이 잘 안되지 않을까 걱정되어 잠을 잘 못잤는데, 다행히 잘 봐주신 것 같습니다. 시상식을 갔다 왔는데, "4등에 특별상까지 타고, 정말 축하한다. 설명 문서 제출하는것도 제일 열심히 쓴 것 같고 정말 열심히 논문도 많이 본 것 같고, 관련 전공자도 아닌 뜬금없는 설비, 소방 학과 학생이 이렇게까지 해줘서 놀랐다. 열심히 참가해줘서 고맙다." 라는 엄청난 칭찬을 들었습니다. 몸둘 바를 모르겠습니다. 제가 더 감사합니다...
이번 학기는 학교에서 전공 과목들을 15주(16주) 수업을 12주로 압축하여 수업을 진행하는 3학년 2학기였는데요, 본전공 과목들, 복수전공 과목들, 졸업 필수 교양 과목들이 15주, 12주 수업이 섞여버렸고, 매주 나오는 과제, 팀플 일정과 중간고사 일정이 모두 겹쳐버리는 등의.... 힘든 학기였습니다. 공부하다 힘들어서 코피를 흘린다는게 다 거짓말인 줄 알았는데, 이번 학기 12주 수업이 진행되는 와중에만 코피를 7번을 흘렸네요. (세수하고보니 주르륵. 주르륵. 주르륵.) 그런 와중에 같이 진행하던 대회였어서 정말 힘들었습니다.
하지만 12주 수업을 했던 과목들의 성적도 만족스럽게 나왔고, 큰 대회에서 좋은 성적을 거뒀고, 상을 한개도 아니고 두개! 나 타서 정말 좋습니다. 4위 수상으로 상금을 받고, 특별상으로는 M1 아이패드 프로(11인치) 를 받았는데, 아이패드 8세대를 쓰고 있던 저에게는 정말 만족스러웠습니다. True Tone 최고... ProMotion 최고... M1 짱짱...
1. 데이터 소개
HAICon2021 산업제어시스템 보안위협 탐지 AI 경진대회 - DACON
좋아요는 1분 내에 한 번만 클릭 할 수 있습니다.
dacon.io
데이터는 여러 파일로 나누어져 있지만 크게 보아 총 3개입니다. 학습용, 검증용, 그리고 테스트, 3개입니다. 데이터는 여러 가지의 센서, 액추에이터의 값인데, 이러한 센서값들을 이용해서, 해당 시스템이 공격을 받는지, 이상이 발생하였는지를 맞춰야 하는 문제입니다. 하지만 무턱대고 진행하면 되는 것이 아니고, 학습 데이터에는 '이상 여부' 가 없이 모두 '정상 상태'의 데이터셋만 존재합니다. 정상 상태의 데이터만을 가지고 학습을 진행하여, 시스템의 이상 여부를 판단해야 하는 문제입니다. 아무래도 이상 상태의 데이터는 정상 상태의 센서와 액추에이터 값이 다를 것이므로, AutoEncoder 를 통한 Anomaly Detection 을 진행하는 것 처럼, 데이터의 복원이 잘 안되면 이상 상태인 것으로 간주할 수 있고, 그 기준선을 정하는 것 역시 필요합니다.
다음 중요한 특징은, 시계열 데이터라는 점입니다. 개인적으로 시계열을 매우 어려워하지만, 돌아보니 시계열에 대한 좋은 기억들이 많아 열심히 해봐야겠다 라고 다짐하였습니다. 무작정 표 데이터여서 MLP 를 만들고 시작하면, 시간 순서를 잘 고려하는 것 보다 낮은 성능을 보일 가능성이 매우 높습니다. 실제로 이 데이터로 한 첫번째 실험이 MLP AutoEncoder 였는데, 아주 엉망이었습니다. 그래서 바로 시계열 모델을 만들어야겠다고 생각했습니다.
2. 모델링
최종적으로 사용한 모델은 MLP-Mixer 를 구현하여 사용하였습니다. 구현한 코드는 여기 에 있는 MLP Mixer 구현을 모델 저장하기 편하게, 사용하기 편하게 개인적으로 수정을 하였습니다.
모델은 일단 '시계열'을 바로 다룰 수 있는 모델이어야 하기 때문에, 우선적으로는 RNN, 1D CNN, CNN+RNN, RNN+CNN, Transformer 들의 구조가 생각이 났습니다. Input 으로 time N 까지의 시계열 시퀀스를 받아, N+1 스텝의 센서 값을 예측하는 것이 목표였습니다. 아예 Seq2Seq 구조 처럼 출력 시퀀스를 뱉어내도록 만들어 볼까 하는 생각도 있었지만, 여러 실험을 하면서 코드를 새로 뜯어 고치기는 너무 바빴습니다. ㅠㅠ
첫번째 시도는, Dacon 에서 제공한 Baseline 코드 처럼 Bidirectional RNN 모델입니다. GRU와 LSTM 모두 실험 해 보았는데, 결과는 영 좋지 않았습니다. 검증 데이터셋에서는 아주 낮은 점수를 보였고, 그에 비해서 테스트 셋에서는 상대적으로 높은 점수를 보였습니다. 여기서 검증데이터와 테스트 데이터가 꽤 차이가 있을 수 있겠구나 라고 생각했습니다.
두번째 시도는 CNN을 같이 이용한 모델을 시험해 보았습니다. 1D CNN만을 이용하여 만든 VGG style 의 모델은 전혀 학습을 하지 못했고, RNN과 CNN이 결합된 모델 역시 마찬가지였습니다.
그 다음 시도한 것은 Transformer 모델입니다. Transformer 는 인코더만 만들어서 사용하였습니다. 예측하고자 하는 Timestep이 1개였기에 굳이 디코더까지 만들지 않아도 될 것이라 생각하였습니다. 그렇게 트랜스포머 인코더를 간단히 구현해서 예측을 하였는데, 점수가 눈에 띄게 상승한 것을 확인했습니다. RNN, CNN과 Transformer 가 다른 가장 큰 포인트, '전체 시퀀스를 한번에 볼 수 있느냐' 의 차이가 큰 효과가 있었다고 생각했고, Transformer 모델을 만들기 시작했었습니다. 하지만 Transformer 모델은 입력 시퀀스 길이를 길게 하여 실험을 하다 보니까, 시간이 너무 오래 걸렸고, 제 컴퓨터로 하기에는 답답해졌습니다.
그래서 최종 결정한 모델이 MLP-Mixer 입니다. MLP Mixer 는 Transformer 처럼 한번에 전체 시퀀스를 다룰 수 있지만, 더 가볍고, 빠르고, VRAM이 모자란 제 컴퓨터에서 더 잘 돌아갈 것 같았고, MultiHeadAttention 과정보다 'Function Approximator' 에 가깝다고 볼 수 있다고 생각했습니다. 이러한 시계열 문제에서 Self Attention이 작동하는 과정은 (수학적으로 정확한 설명은 아니지만), Sequence 내의 각 Timestep간의 연관성, 중요도를 계산하는 것이라 생각했습니다. 하지만 MLP Mixer 는 각 Timestep 간의 연관성, 혹은 중요도, 관계를 파악하는 것이 아니라 함수로 표현하는 것이라 생각해서, 이것도 충분히 가능성 있는 모델이라고 생각했습니다. 제가 이해하고 있는 두 모델의 차이를 키노트로 그려 보았는데, 아래 그림과 같습니다.

하지만 MLP-Mixer 를 구현하여 학습을 진행해보니, 너무 빠르게 Overfit 되는 현상이 있었습니다. 그래서 MLP Mixer 에다가 Sharpenss Aware Minimization 을 추가해서 학습하기로 생각했습니다. 이 논문(When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations) 에서 보면, ViT와 Mixer 의 학습을 SAM 을 이용해서 도울 수 있다고 나와있습니다. 그래서 Mixer 와 SAM을 같이 써서 Overfitting 을 줄이고, Transformer + SAM 모델보다 더 빠르게 많은 모델을 만들어서 결과물을 앙상블 하는 것이 더 효율적으로 좋은 결과를 낼 것이라 생각하였습니다. 하지만 가장 큰 이유는, MLP-Mixer 논문 마지막 부분에, '다른 도메인에서도 잘 먹히는지 봐도 좋을 것 같다' 고 쓰여있어서 시도해본 것이 결정적 이유였습니다.
MLP-Mixer 를 구현하고 나서, 어느 정도 성능이 잘 나오는 것을 확인하였습니다. 1D CNN, RNN보다 Transformer 와 Mixer 의 성능이 높게 나오는 것을 보아, 전체 Sequence 를 한번에 보고 처리하는 모델이 더 잘 작동하고 있고, 두 모델 모두 컴퓨터에서 돌아가는 선에서는 성능이 유사하게 나온다면, 복잡한 모델보다 단순한 모델이 낫다는 생각으로 MLP-Mixer 를 여러 타임스텝에 맞춰 Scale Up, Scale Down 한 16개의 모델을 만들고, 그 앙상블 모델을 최종 모델로 선택했습니다. MLP AutoEncoder 를 만들 때, 무작정 층 수를 늘리거나 뉴런 수를 많게 한다고 반드시 좋은 모델이 되지 않는다는 생각과 맥락을 같이 합니다.
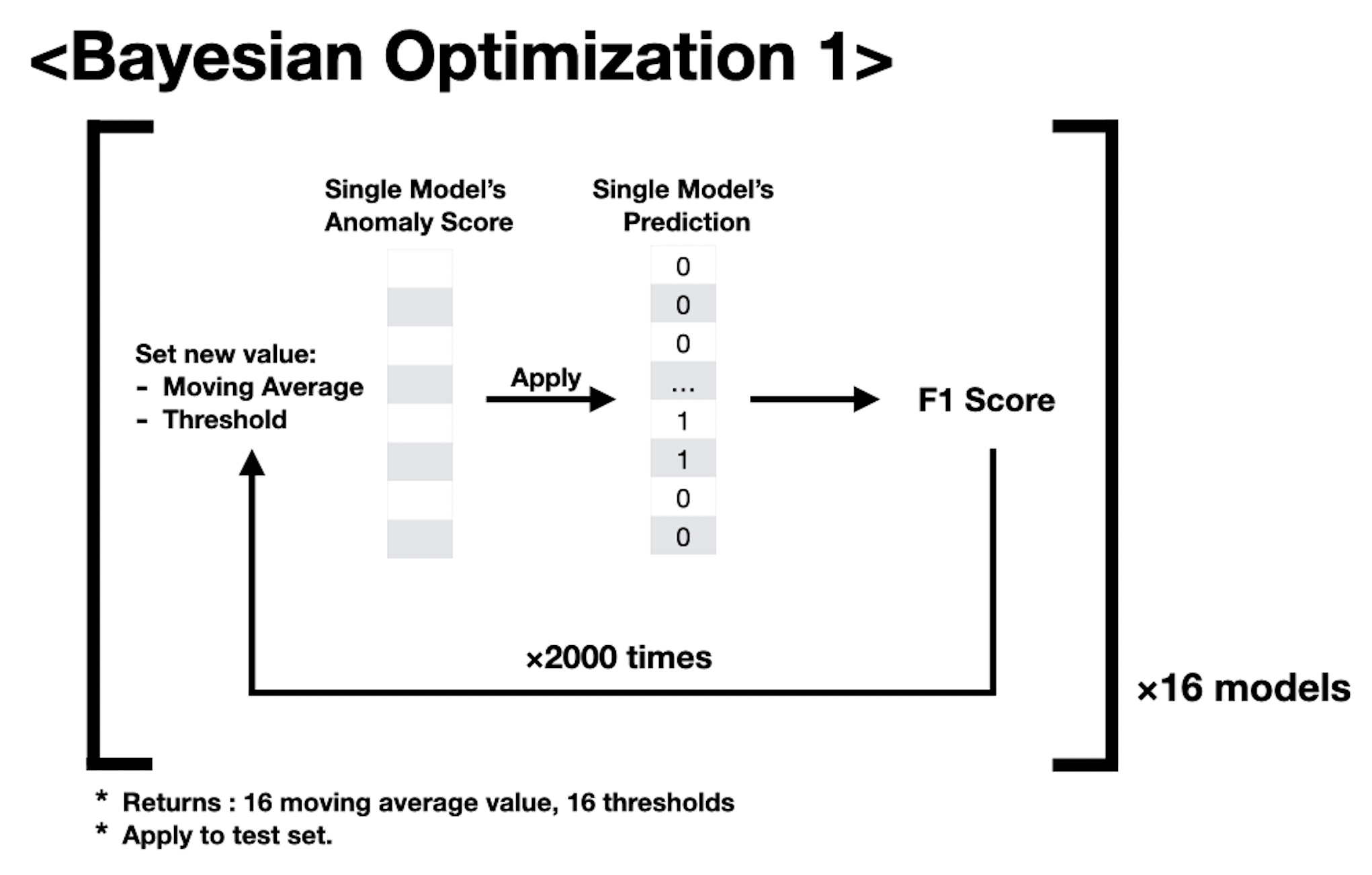
모델만큼 성능에 중요한 영향을 끼친 부분은 Threshold 를 정하는 일이었습니다. Threshold 는 optuna 를 사용하여 2000회의 반복을 통해서 결정하였습니다. 무작정 RandomSearch 를 하는 것 보다는 Bayesian Optimization 을 하는 것이 좋다고 판단했고, 평소 하이퍼파라미터 튜닝에 optuna 를 많이 사용해서 익숙한 함수를 만들듯이 적용할 수 있었습니다. 먼저 16개 예측값에 대하여, 이동 평균을 이용해 예측 결과물을 smoothing 시키고, threshold 를 결정해 [0, 1, 0, 0, ...] 과 같은 예측 결과물을 만들었습니다. 적용할 이동평균 값과 threshold 를 아래 그림과 같이 반복을 통하여 구했습니다.
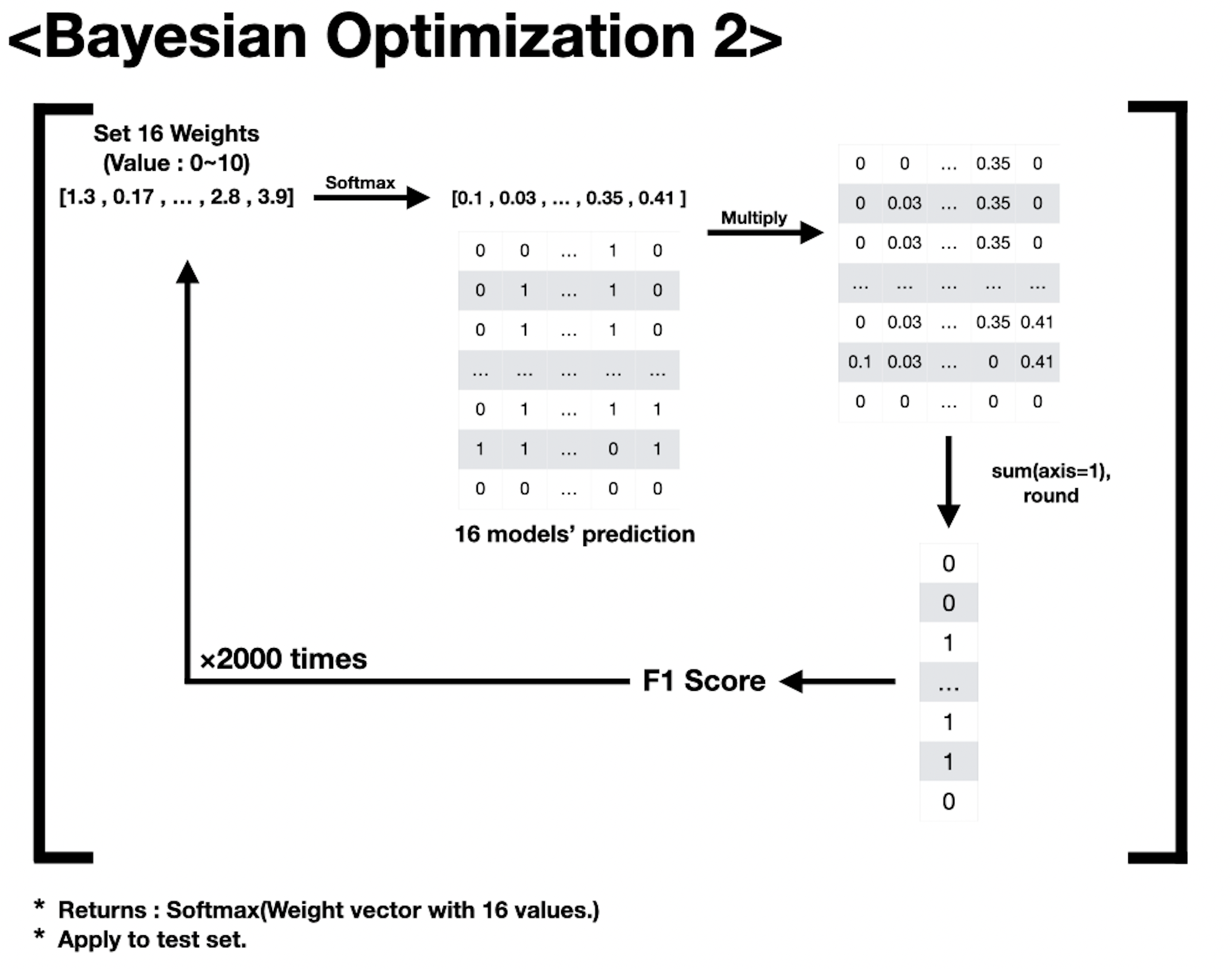
다음으로는 16개 예측 결과를 조합하는 과정 역시 optuna 를 이용해서 만들었습니다. 0과 1로 이루어진 예측 결과물들을 softmax 함수를 거친 weight vector 를 통해 Soft Voting 하도록 하였습니다.
이러한 파이프라인을 만들었는데, 이 과정에서 가장 큰 문제는 검증 데이터에 대한 Overfitting 이 매우 잘 일어난다는 점이었습니다. 2020년 대회에 적용했을 때는, 먼저 예측값을 만들고 Voting 하는 것이 그닥 좋은 결과를 내지 못했는데, 2021년 대회에는 잘 적용되는 것을 확인했습니다. 제가 내년 대회에도 참여하게 될지는 잘 모르겠는데, 이 부분은 실험을 통해서 대회마다 다르게 적용되어야 할 것 같습니다.
3. 결론, 느낀점
검증데이터셋의 활용이 정말 힘들었던 대회였습니다. 학습에는 절대 사용하면 안되지만, Early Stopping 을 걸거나, 검증 데이터셋 일부를 학습 데이터셋에 포함시켜서 Scaling 하는 것은 허용되었고, 검증 데이터셋 점수와 테스트 데이터 점수가 일관성이 별로 없게 나와서 혼란이 많았던 대회라고 생각합니다.
2020년에도 HAICon이 진행되었는데, 1년 전에 저는 이 과정을 이해를 못하고, 1D CNN으로 만든 모델 3번 만들어보고, 대회가 이해가 되지 않아 포기했었던 기억이 납니다. 비슷한 시기에 올해도 비슷한 대회가 진행되어서, 1년 사이에 제가 조금은 성장했구나 라는 생각이 들어서 기뻤고, 좋은 결과까지 얻어서 더욱 기쁩니다. Public LB에서 7위였기 때문에 3등 안으로 들어가는 것은 상상도 하지 못했었고, Private LB도 뚜껑을 열어 보니 3등팀과의 점수 차이는 어마어마해서, 4등에 매우 만족하고있습니다. 더 열심히, 정진하도록 하겠습니다.
