처음으로 대회에서 상금을 받게 되었다. 대회 마감시간인 8월 14일 오후 6시, Private 랭킹이 결정된 후 너무 신나서 방방 뛰었던 기억이 난다.

처음으로 상금을 수상하게 되었고, 데이콘 측에 블로그에 글을 올려도 되냐고 물어보았는데, 가능하다는 답변을 받았다.
수상자들은 데이콘 코드공유 페이지에 코드를 올려서 코드 검증을 받아야한다.
음성 중첩 데이터 분류 AI 경진대회
출처 : DACON - Data Science Competition
dacon.io
(출처 : 데이콘에 올렸던 코드 원본 (위 링크))
1. Load Data
import os
import pandas as pd
import numpy as np
import scipy
from tqdm import tqdm
from glob import glob
from scipy.io import wavfile
import librosa
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import time
sns.set_style('whitegrid')
import warnings ; warnings.filterwarnings('ignore')
def data_loader(files):
out = []
for file in tqdm(files):
data, fs = librosa.load(file, sr = None)
out.append(data)
out = np.array(out)
return out
Xtrain = glob(data_dir + 'train/*.wav')
Xtrain = data_loader(Xtrain)
Ytrain = pd.read_csv(data_dir + 'train_answer.csv', index_col='id')
submission = pd.read_csv(data_dir + 'submission.csv', index_col='id')
print(Xtrain.shape, Ytrain.shape)
time.sleep(1)
Xtest = glob(data_dir + 'test/*.wav')
Xtest = data_loader(Xtest)
Xtrain = Xtrain.astype('float32')
Xtest = Xtest.astype('float32')
print(Xtrain.shape, Ytrain.shape, Xtest.shape, submission.shape)언제나 그랬듯 비슷한 단계이다. 이번 대회는 음성 데이터를 다루는 대회여서, 데이터를 받으면 train 폴더 안에는 약 10만 개의 음성 파일이 wav 파일로 저장되어있고, test 폴더에는 1만 개의 음성 wav 파일이 들어있다.
wav 파일을 처음 다뤄보아서 어떻게 해야할지 손도 못대고 있던 와중에 데이콘에서 제공한 baseline 코드가 올라왔다. Scipy 를 이용해서 wav 파일을 불러오는 코드였다. 코드를 약간 바꿔서 librosa 패키지로 음성파일을 불러왔다.
Scipy 와 librosa 는 음성을 로딩한 결과물이 다른데, scipy에서는 +-30000 으로 원래의 값이 그대로 담겨있는 numpy array 가 생겼고, librosa 는 로딩된 데이터를 자동으로 +- 1 의 범위로 normalize 되어서 로딩되었다. 그래서 이렇게 느린거였나
2. Preprocessing
def get_melspectrogram(data, n_fft, win_length, hop_length, n_mels, sr=16000, save=False, to_db=True, normalize=False):
array = []
for i in tqdm(range(len(data))):
melspec = librosa.feature.melspectrogram(data[i], sr=sr, n_fft=n_fft, win_length=win_length,
hop_length=hop_length,n_mels=n_mels)
array.append(melspec)
array = np.array(array)
if to_db == True:
array = librosa.power_to_db(array, ref = np.max)
if normalize==True:
mean = array.mean()
std = array.std()
array = (array - mean) / std
if save == True:
np.save(f"{data_dir}mel_spectrogram({n_fft},{win_length},{hop_length},{n_mels}).npy", array)
return array
def gen_4_mels(data, normalize=True):
alpha = get_melspectrogram(data, n_fft=256, win_length=200, hop_length=160, n_mels=64, save=False, to_db=True, normalize=normalize)
beta = get_melspectrogram(data, n_fft=512, win_length=400, hop_length=160, n_mels=64, save=False, to_db=True, normalize=normalize)
gamma = get_melspectrogram(data, n_fft=1024, win_length=800, hop_length=160, n_mels=64, save=False, to_db=True, normalize=normalize)
delta = get_melspectrogram(data, n_fft=2048, win_length=1600, hop_length=160, n_mels=64, save=False, to_db=True, normalize=normalize)
data = np.stack([alpha, beta, gamma, delta], axis=-1)
return data음성 데이터를 처리하는 법에 대해서 찾아보니 몇가지 방법으로 요약되는 것 같았다.
- 파일 하나하나가 시계열이므로 RNN 으로 처리
- 1D-CNN 으로 처리
- MFCC, 또는 (Mel-) Spectrogram 으로 변환해서 2D-CNN으로 처리
모델을 만들면서는 RNN 만 빼고 1D CNN, MFCC, Mel-Spectrogram 3가지를 시도해보았었다. RNN 만들줄몰라요 1D-CNN 으로 원래 음성 파일을 그대로 다루는것 보다, MFCC 가 결과가 더 좋았고, MFCC 보다는 Spectrogram이, Spectrogram 에서도 원래 스펙트로그램인 Mel Power Spectrogram 보다 이 값들을 dB로 바꿔준 dB Mel Spectrogram (그냥 이름 붙임) 이 결과가 제일 좋았다.
데이콘에 코드 공유를 올리면서도 적어두었는데, 이번 대회에서는 음성 데이터의 ㅇ 자도 모르던 내가 코드 공유해주신 고수분들의 덕을 톡톡히 봤다고 해야 할 것 같다. 출처 : 우승하신 JunhoSun 님의 설명글 (from 데이콘 코드 공유)
'마지막으로 spectrogram과 melspectrogram의 해상력에 대해 설명하겠습니다. win_length가 커질수록 주파수 성분에 대한 해상력은 높아지지만, 즉 더 정밀해지지만, 시간 성분에 대한 해상력은 낮아지게 됩니다. 즉, 더 정밀한 주파수 분포를 얻을 수 있으나 시간에 따른 주파수 변화를 관찰하기가 어려워집니다. 반대로 win_length가 작은 경우에는 주파수 성분에 대한 해상력은 낮아지지만, 시간 성분에 대한 해상력은 높아지게 됩니다. 따라서 적절한 값을 찾는 것이 중요합니다.' - JunhoSun / 음성 신호 기본 정보 / (월간 데이콘 6 우승)
나의 능력으로 적절한 값 하나를 찾아낼 수는 없을 것 같아서 데이터를 여러 개 만들어서 합치기로 했다. 딥러닝은 나보다 똑똑하니까. 몇개의 mel spectrogram 을 만들다보니, 이 스펙트로그램의 크기는 hop_length 와 n_mels 로 결정된다는 것을 찾을 수 있었다.
이 값들에 대한 설명도 위 링크에서 내용을 찾아볼 수 있었다.
- n_fft : win_length의 크기로 잘린 음성의 작은 조각은 0으로 padding 되어서 n_fft로 크기가 맞춰집니다. 그렇게 padding 된 조각에 푸리에 변환이 적용됩니다. n_fft는 따라서 win_length 보다 크거나 같아야 하고 일반적으로 속도를 위해서 2^n의 값으로 설정합니다.
- win_length : 이는 원래 음성을 작은 조각으로 자를 때 작은 조각의 크기를 의미합니다. 자연어 처리 분야에서는 25m의 크기를 기본으로 하고 있으며 16000Hz인 음성에서는 400에 해당하는 값입니다.
- hop_length : 이는 음성을 작은 조각으로 자를 때 자르는 간격을 의미합니다. 즉, 이 길이만큼 옆으로 밀면서 작은 조각을 얻습니다. 일반적으로 10ms의 크기를 기본으로 하고 있으며 16000Hz인 음성에서는 160에 해당하는 값입니다.
- n_mels : 적용할 mel filter의 개수를 의미합니다.
아하. 처음 보는 말들이다. 이중에서 이 win_length 의 값에 따라서 시간성분 vs 소리성분 어느 것을 더 잘 뽑아낼 수 있느냐 가 결정된다고 한다. 32, 40, 64, 128 의 값들 중에서 n_mels 를 최대한 많이 하려고 했는데, 의 n_mels 가 128개가 되었을때는 에러가 나고 있었다.
Empty filters detected in mel frequency basis. Some channels will produce empty responses. Try increasing your sampling rate (and fmax) or reducing n_mels. warnings.warn('Empty filters detected in mel frequency basis.')
라고 하는데, 나의 경우 4개의 mel spectrogram 모두에서 에러메시지가 출력되지 않는 가장 큰 값이 64였어가지고 64개로 설정했다.
all_data = np.concatenate([Xtrain, Xtest], axis=0)
print(all_data.shape)
time.sleep(1)
all_dbmel = gen_4_mels(all_data, normalize=True)
Xtrain_dbmel = all_dbmel[:len(Ytrain)]
Xtest_dbmel = all_dbmel[len(Ytrain):]
print(Xtrain_dbmel.shape, Ytrain.shape, Xtest_dbmel.shape)이게 하나하나 처리하다 보니 속도가 정말 느리다. Xtrain, Xtest를 합쳐서 4개 채널을 가진 mel spectrogram 으로 만들어주고, 케라스에 넣기 위해 Z-Score Normalization을 했다.
3. Build Model & Train
import keras
import keras.backend as K
from keras.models import Model, Sequential
from keras.layers import Input, Convolution2D, BatchNormalization, Activation, Flatten, Dropout, Dense, Add, AveragePooling2D
from keras.callbacks import EarlyStopping
from keras.losses import KLDivergence
from sklearn.model_selection import train_test_split
from keras.optimizers import Nadam
def mish(x):
return x * K.tanh(K.softplus(x))
def eval_kldiv(y_true, y_pred):
return KLDivergence()(np.array(y_true).astype('float32'), np.array(y_pred).astype('float32')).numpy()케라스를 불러오고, KL-Divergence 를 계산할 수 있게끔 함수도 만들었다.
def build_fn():
dropout_rate=0.5
model_in = Input(shape = (Xtrain_dbmel.shape[1:]))
x = Convolution2D(32, 3, padding='same', kernel_initializer='he_normal')(model_in)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(32, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(32, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Convolution2D(64, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(256, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(64, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(256, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(64, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(64, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(256, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Convolution2D(128, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(512, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Convolution2D(128, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(512, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Activation(mish)(x)
x = Convolution2D(128, 1, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(128, 3, padding='same', kernel_initializer='he_normal')(x)
x = Convolution2D(512, 1, padding='same', kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x, x_res])
x = Activation(mish)(x)
x = AveragePooling2D()(x)
x = Dropout(rate=dropout_rate)(x)
x = Flatten()(x)
x = Dense(units=128, kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x_res = x
x = Activation(mish)(x)
x = Dropout(rate=dropout_rate)(x)
x = Dense(units=128, kernel_initializer='he_normal')(x)
x = BatchNormalization()(x)
x = Add()([x_res, x])
x = Activation(mish)(x)
x = Dropout(rate=dropout_rate)(x)
model_out = Dense(units=30, activation='softmax')(x)
model = Model(model_in, model_out)
model.compile(loss=KLDivergence(), optimizer=Nadam(learning_rate=0.002))
return model
build_fn().summary()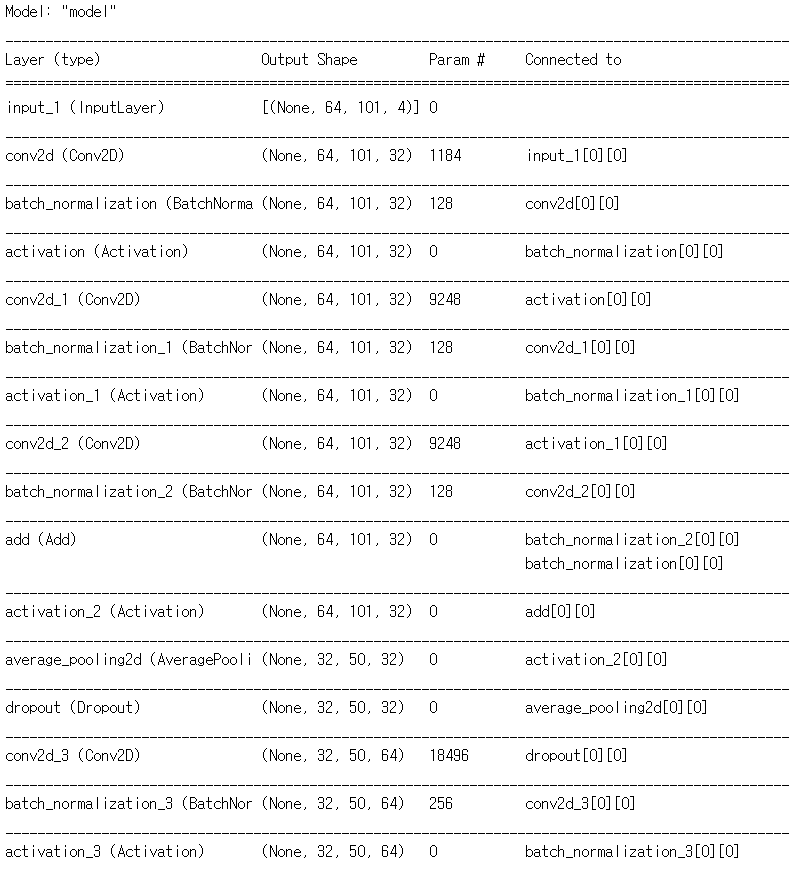
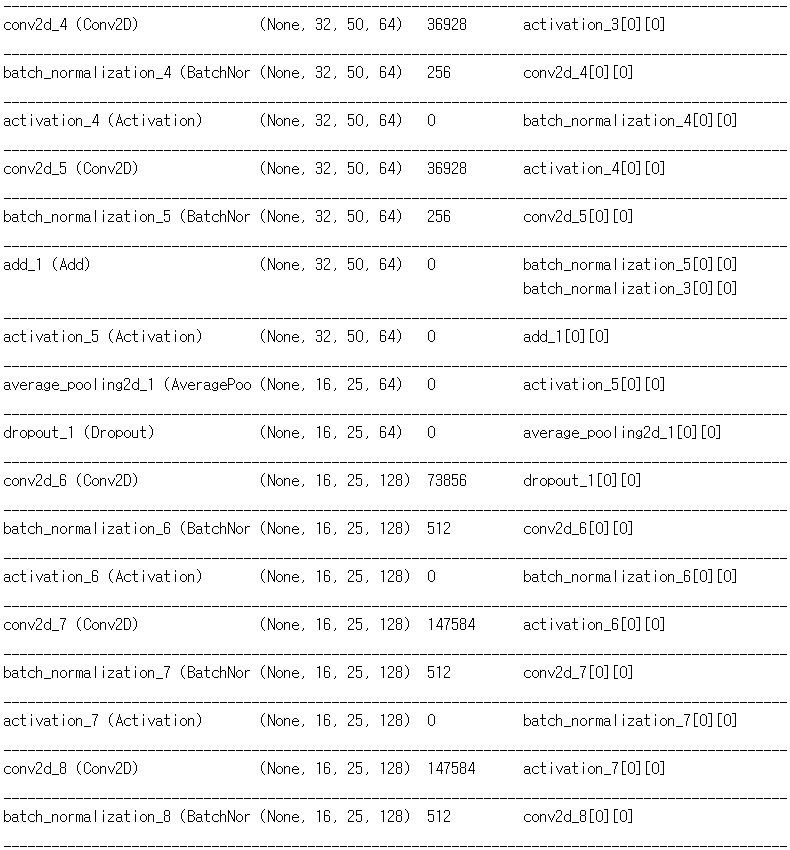
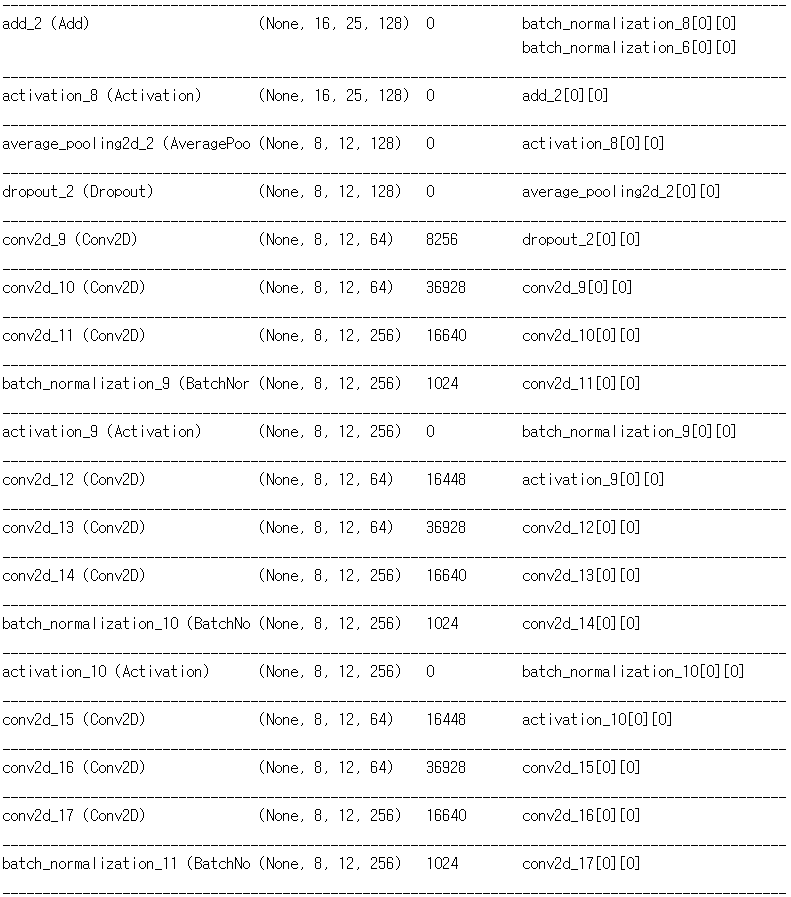
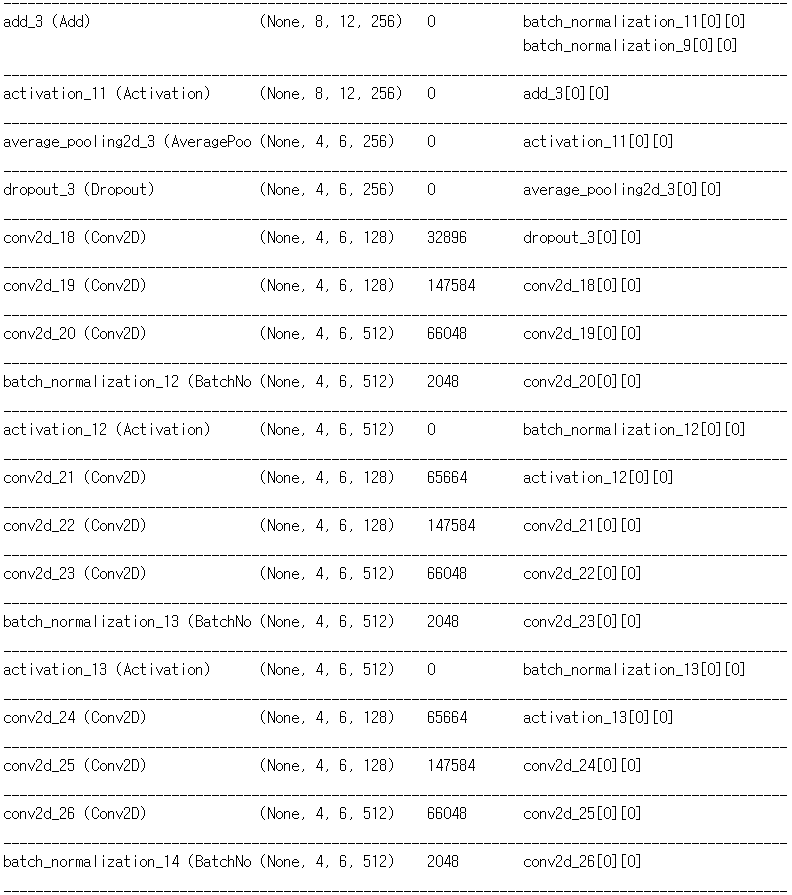
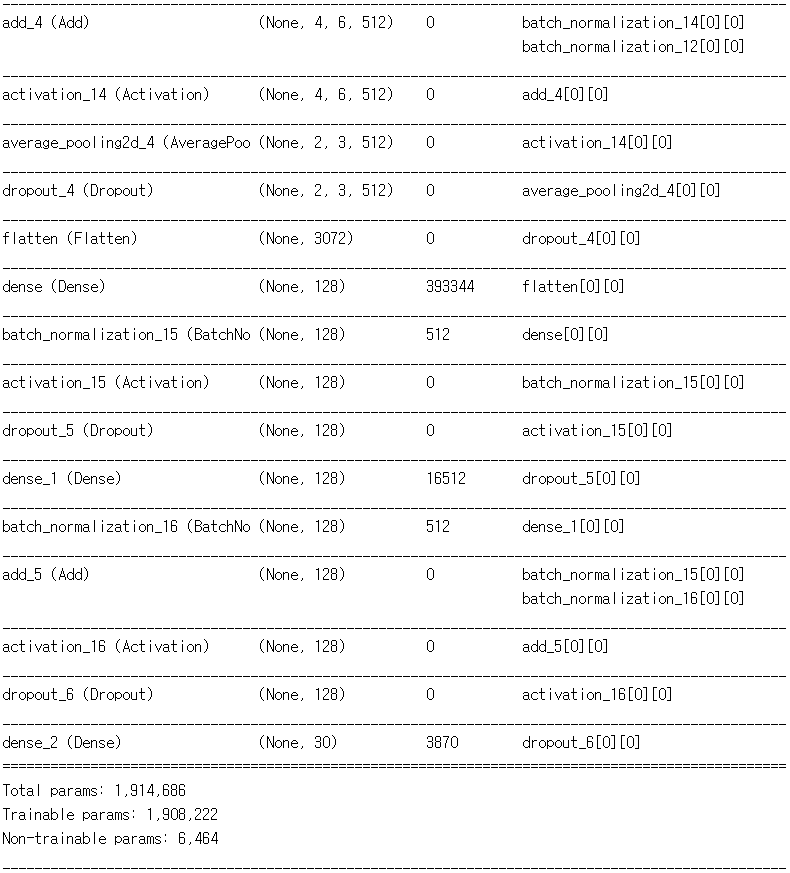
Convolution 의 필터 수를 32, 64, 128, 256, 512 이렇게 5스텝으로 늘어나게끔 구성했다. Convolution 과 BatchNormalization 은 빅맥과 콜라처럼 한 세트로 보고 같이 묶었다. 이 모델을 만들던 시기에 ResNet 에 대해서 알게 되었다. 단순히 이전 레이어의 값을 뒷 레이어에 더해주는 행동 하나로, 깊은 신경망에서 학습이 더 잘된다고? 나도 얼른 적용해보았다. 어떻게 생겼는지 찾아도 보고, 따라해본다고 따라했는데, 비슷하게 따라한 것 같지는 않다. 그냥 텐서 크기가 같은 적절한 위치에서 뽑고, 더하고. 근데 나중에 CNN 깊게 만들때도 이거 있고 없고 차이가 '아주 약간' 났었다.
필터 수가 256, 512 일때는 ResNet 의 BottleNeck 구조를 이용했다. 기본적으로 Convolution 은 선형 연산이기 때문에, 나처럼 ConvConvConv 를 연속해서 하면 똑같은거라고 하지만 그냥 '최종적인 필터 수 256 (또는 512) 이면서, 파라미터 갯수 줄이기) 가 목적이었어서 그냥 ConvConvConv 를 적용해보았다. 그냥 BottleNeck 없이 Convolution 을 했으면 어떨까 궁금하다. 데이터가 크고 많을 수록 적합에 필요한 파라미터도 많을 것이기 때문에... 해볼만한 시도였던 것 같다.
num_models=15
model_list=[]
for i in tqdm(range(num_models)):
model = build_fn()
model.fit(Xtrain_dbmel, Ytrain, epochs=187, batch_size=16)
model_list.append(model)
model.save(f"model_{i}.h5")이렇게 모델을 15개를 만들었다. 위 모델은 단일 모델을 만들면서 실험하면서 가장 점수가 좋았던 모델이고, early stopping 을 걸면서 에폭수 187 을 찾고, 배치 사이즈도 32, 16 을 했을때 16이 점수가 더 좋았어서 최종 선택했다.
RTX 2060 Super(8GB) 그래픽카드로 모델을 1개 학습시키는데 약 9시간 30분이 걸렸다.
코드는 이렇게 15개를 한번에 넣고 실행했지만, 실제로는 5개 하고 제출하고, 5개 더하고, 제출하고 했는데, 각각 결과는
- 5개 단순 평균 : 0.41778
- 10개 단순 평균 : 0.40481
정도이다.
preds = np.zeros(shape=submission.shape)
train_preds = np.zeros(shape = Ytrain.shape)
train_preds_list=[]
test_preds_list=[]
score_list=[]
for model, i in zip(models, range(len(models))):
a = model.predict(Xtrain_dbmel)
b = model.predict(Xtest_dbmel)
eval_score = eval_kldiv(Ytrain, a)
print(f"Model {i+1} Evaluation Score : {eval_score}")
train_preds = train_preds + a
preds = preds + b
train_preds_list.append(a)
test_preds_list.append(b)
score_list.append(eval_score)
train_preds = train_preds / len(models)
preds = preds / len(models)
print(f"\nMean Predictions Evaluation Score : {eval_kldiv(Ytrain, train_preds)}")
simple_average = pd.DataFrame(preds, index=submission.index, columns=submission.columns)
simple_average.to_csv('15 Average Ensemble model.csv')
simple_average.head(10)예측 결과물들을 단순 평균을 내는데, 단순 평균만 해도 점수가 확 좋아지는 것을 확인할 수 있었다.

와우~~ 이렇게 점수가 확 좋아진것은 KL-Divergence 의 특성 때문인 것 같다.
KL-Divergence 는 맞춰야 할 값을 잘 못맞추더라도, 조금이라도 값을 잡고, 안잡고에 따라서 점수가 확 차이가 난다고 한다. 아무래도 평균을 내면, 조금이라도 값을 잡는 경우가 많아지기 때문이라고 생각한다.
15개 예측값들의 최종 평균 점수는
Simple Average of 15 Predictions
- Public LB : 0.399484
- Private LB : 0.39202
4. 마지막으로 할 말
으아으아으아으아감사합니다유ㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠ
처음으로 상금을 받았다. 운도 잘 따라준 것 같고, 내 능력 안에서 내가 해야하는 노력도 할만큼 했다고 생각한다. 코드 검증도 끝나고, 계약서도 쓰고, 최종적으로 9월 8일에 상금을 받았다. 불과 1년 반 전까지만 해도 나는 간신히 타이타닉 코드 따라 치면서 외우고, 손에 파이썬이란것을 처음으로 익히고 있었던 중이었는데, 저번 대회부터 랭킹 안에도 들었고, 이제는 돈도 받아봤다! 원래는 게이밍 노트북에(i5-8세대, GTX 1060) 램을 16G 로 업그레이드하고 1TB HDD 를 가상메모리용으로 두고 하던 중이었는데, 너무 느려 터지고, 데이터 불러오는것도 한세월, 한 에포크 도는거 두세월씩 걸려버리니까 너무 화가 나서 반드시 상금 타겠다는 각오로 들고있던 돈을 모두 때려 넣어서 컴퓨터를 바로 새로 샀다. 역시 귀족학문
그냥... 뭐...음... 아직까지는 이렇게 대회하는 것이 재미있다. 이걸로 일을 하게 된다면 어떻게 될까는 아직 잘 모르겠지만, 전과도 일단은 보류중이기 때문에 머신러닝 대회는 정말 취미가 된 상태지만, 아직까지는 대회 하는게 재미있다. 앞으로도 좀 더 잘 해봐야겠다.
상금은 좋은 곳(이라 쓰고 컴퓨터 투자금 회수) 에 쓰겠습니다.
