Titanic: Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
머신러닝에 입문하는 사람들이라면 누구나 들어봤을, 모두가 머신러닝 입문용으로 시작하는 바로 '그' 경진대회이다. 그 이름은 타이타닉. 나도 타이타닉으로 머신러닝에 입문했었다. 지금은 약 1년 몇 개월 전의 일이네. 내가 지금까지 참가한 대회 중에서 가장 성적이 높은 대회이기도 하다...(눈물 주르륵 광광)

데이콘이라는 사이트에서도 타이타닉 컴퍼티션이 있다. 참고로 캐글에서 0.82296의 점수는 (2020년 3월 4일 기준) 16000여 명 중에서 471등을 기록하고 있다. 캐글의 타이타닉 대회에서는 점수 측정공식이 '정확도' 인 반면, 데이콘에서는 'RMSE' 를 사용한다. RMSE를 사용한다면, 아무래도 데이터를 사망 여부 (사망시 0, 생존시 1) 로 딱딱 떨어지게 예측하기보다는, 생존 확률 (0.6인경우, 60퍼센트의 확률로 생존 가능성) 로 결과물을 제출하는 것이 더 낫기 때문에, 코드의 마지막 줄만 바꾸어서 데이콘에 제출했더니 3위이다.

뭐 이런 튜토리얼성 경진대회 잘한다고 실력이 좋은, 뛰어난 데이터 사이언티스트의 싹이 보인다는 뜻은 당연히... 맞을 수도 있지만 아닐 가능성도 있다. 그래도 입문하면서 점수가 잘 나오면, 기분이 매우 좋다! 나는 처음 캐글을 시작하면서 랭킹이 바로바로 업데이트 되는 것을 보고 아주 환장을 하고 죽기살기로 덤볐었다. 랭킹 몇 등 올리는것이 당시 나에게는 세상 그 무엇보다도 재미있는 일이었다.
아무튼, 나는 이 코드를 이미 캐글에 수백 번 제출했었고, 내가 하는 스터디에서도 발표했었고, 캐글 노트북(캐글 커널) 에도 업로드를 했었고, 아주 수도 없이 우려먹었었지만, 이제 마지막으로 우려먹으려고 한다. 이 블로그에 나의 머신러닝에 관한 모든 기록을 담아서 보관할 예정이라서, 여기에도 업로드를 하려고 한다.
아마 구글 검색해서 나오는 코드들중에서는 내 코드가 가장 쉬울 거라고 생각한다.... 아무리 봐도 내 코드는 너무 쉬워보인다..
머신러닝에 입문하는 사람들에게 약간이나마 도움이 되었으면 합니다.
지식은 고여있으면 썩는 법이니까.
21.02. - 처음에는 리더보드가 test 일부만 가지고 채점되어서 0.82296이었는데, 현재는 test 전체를 이용해서 채점하기 때문에 점수가 바뀌었습니다. 0.79186이네요. 데이콘에서도 지금은 RMSE를 사용하지 않습니다!
1. 패키지 로드
import pandas as pd
import numpy as np
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
간단히 설명을 하자면
pandas : 데이터 (주로 행렬 데이터) 를 분석하는데 쓰이는 파이썬 패키지. 특히 표 데이터를 다룰때 거의 무조건 사용한다.
numpy : 선형대수 연산 파이썬 패키지. 그냥 수학 계산을 편하고 빠르게 할 수 있는 패키지라고 생각하면 쉽다.
%matplotlib.inline : 그래프를 주피터 노트북 화면상에 바로 띄울 수 있게 하는 코드. 근데 없어도 seaborn 그래프 잘만 되더라.
seaborn : 쉽고 직관적인 방법으로 그래프를 띄울 수 있는 패키지.
matplotlib.pyplot : matplotlib 라는 그래프 띄우는 패키지 중 일부. 나는 여러개의 그래프를 한 결과로 띄우고 싶을때만 주로 사용한다.
norm : 정규분포를 의미. 데이터의 분포 그래프를 띄울때, 이 norm 을 불러와주면 정규분포랑 손쉽게 비교해 볼 수 있다.
2. 데이터 로드
train=pd.read_csv('train.csv', index_col='PassengerId')
test=pd.read_csv('test.csv', index_col='PassengerId')
submission=pd.read_csv('gender_submission.csv', index_col='PassengerId')
print(train.shape, test.shape, submission.shape)train.csv, test.csv, submission.csv 이 세 파일이 지금 작업하고있는 주피터 노트북과 같은 폴더 안에 있을 때 작동한다. 만약 다른 폴더에 있다면, '/Users/뭐시기/뭐시기/Desktop/train.csv' 처럼 경로를 지정해준다면 잘 열릴 것이다.
pd(판다스) 의 'read_csv' 라는 메소드를 이용해서 csv 파일을 쉽게 읽어올 수 있다. 'index_col' 은 해당 열을 (여기서는 승객번호) 인덱스로 사용할 수 있게끔 해준다. 이후에 데이터를 보면 알겠지만, 승객번호는 1번, 2번, 3번, .... 800몇번 이런식으로 쭉 증가하는 고유한 값이기 때문에 나는 이 열을 인덱스로 사용했다.
마지막 print 문을 실행하면 결과는 아마
(891, 11) (418, 10) (418, 1)
이라고 출력이 될 것이다. 이 괄호 안의 숫자들이 우리가 읽어온 데이터 행렬의 크기를 나타낸다. 표시되는건, (행 숫자, 열 숫자) 로 출력이 된다. 우리는 train.csv 에 있는 891명의 승객 데이터를 가지고, test.csv 에 있는 418명의 생존 여부를 예측해서 제출해야 한다는 의미이다.
3. 데이터 분석 시작
이제 남은 일은 내 입맛대로 데이터를 분석하고 요리하면 되는 것이다. 내가 행렬 데이터를 보면 항상 하는 순서가 있는데, 그 순서대로 해보겠다.
이렇게 데이터의 열에 '이름' 이 붙어있다면, 데이터를 분석할 때 상식적인 선에서의 '가설' 을 세우고 접근하는 방법이 있다. 예를 들면, 여성이 남성보다 생존 확률이 높을 것이다. 어린이들은 생존 확률이 높을 것이다. 라는 등의 가설을 세울 수 있겠다. 이는 경우에 따라서는 상당히 좋은 방법이다. 일반적인, 그니까 상식적인 수준에서 가설을 세울 수 있다면 데이터 분석 과정을 상당히 빠르게 해낼 수 있다. 다만, 데이터가 '익명화' 되어서 데이터 열에 이름이 없는 경우, 가설을 세우기가 상당히 어려워진다. 또한, 해당 분야의 배경지식이 필요한 전문 분야의 데이터일수록 가설 세우기는 더더욱 어렵게 된다. 전문 지식이 있으면 좀 낫겠지만. 하지만 1년 몇개월 간의 짧은 경험 상으로는 없다고 해서 크게 문제되지는 않았다. '컴퍼티션 진행하는데 배경 지식이 있으면 훨씬 쉬웠겠지만, 없어도 지장은 없다.' 정도의 느낌을 받았다.
3.1. 타겟 변수 확인
먼저 우리가 예측해야하는 '생존 여부' 가 어떻게 이루어져 있는지 보자. 생존 여부는 train 데이터에만 있고 test 에는 없다. 우리는 train 데이터에서 주어진 승객들의 정보와 그들의 생존 여부를 머신러닝에게 학습하도록 하고, test 데이터에 존재하는 승객들의 생존 여부를 맞출 것이다. 이렇게 우리가 맞춰야 하는 데이터를 타겟 변수(target variable), 혹은 종속 변수 라고 부른다. 나는 거의 타겟 변수라고 많이 부른다.
sns.countplot(train['Survived'])
train['Survived'].value_counts()
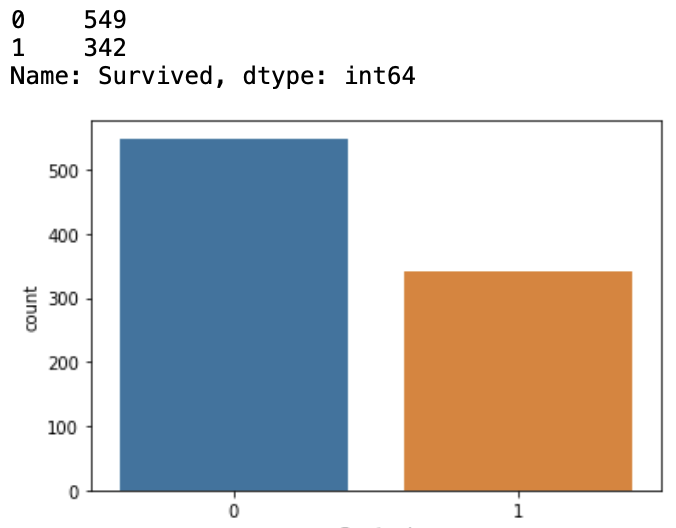
아마 이런 결과물이 나올 것이다. 0이 사망자, 1이 생존자를 의미한다. 그래프를 보면 사망자의 수가 생존자의 수보다 더 많은 것을 알 수 있다.
데이터별로 이런 타겟 변수가 한쪽의 값만 지나치게 많은 경우, 우리는 이를 'Class imbalanced problem' 이라고 부른다. 카드 사기 거래 여부, 하늘에서 운석이 떨어지는 경우를 예를 들어 보면 사기가 아닌경우, 운석이 떨어지지 않을 경우가 반대의 경우보다 그 수가 압도적으로 많다. 이때 별다른 처리 없이 머신러닝에게 데이터를 학습시킨다면, 머신러닝이 모든 데이터를 0(사망, 혹은 정상거래, 혹은 운석 안떨어짐) 이라고 예측할지도 모른다. 그리고 이 정확도를 보면, 상당히 높게 나온다. 실제로 우리가 예측하려는 데이터에도 운석이 떨어지는 날은 몇일 되지 않을 것이니까. 하지만 이 녀석은 참으로 의미없는 머신러닝 모델이 될 것이다. 실제로 우리나라 일기예보도 '365일 비 안옴' 이라고 예측하면 정확도가 75% 정도 된다고 하지만, 이것이 의미있는 예측은 아니지 않은가. 이럴때는 여러 방법들을 통해 이 불균형을 해결한 후 머신러닝 알고리즘으로 학습을 시켜야 의미있는 예측을 하는 경우가 대부분이다. 그리고 타이타닉 데이터에 있는 이 불균형정도면, 상당히 양호한 편이라고 할 수 있다.
참고로, 모든 승객을 사망 이라고 처리하고 제출해도 캐글 정확도는 약 60% 가 넘게 나온다.
3.2. 결측치 처리
print(train.isnull().sum())
print(test.isnull().sum())실행하면 아마 다음과 같은 결과가 나올 것이다.
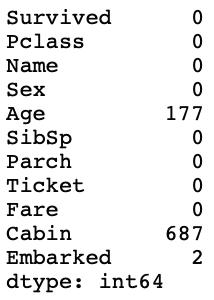

결측치는 말 그대로 측정하지 못한 값이다. 'Age' 와 'Cabin' 열에서 결측치가 특히 많이 발생한 것을 볼 수 있다. 생각해보면 결측치는 '없는 데이터' 이기 때문에, 머신러닝이 여기서 배울 수 있는것은 전혀 없다. 그리고 사용하는 머신러닝 알고리즘에 따라서 데이터에 결측치가 있는 경우 에러가 날 수도 있다. 결측치를 처리하는 방법으로는, 결측치가 있는 데이터를 지워버리는 방법도 있고, 주변값 또는 대표값으로 결측치를 채워 넣는 방법도 있다. 나는 일단 Cabin 을 먼저 지워버려야겠다.
train=train.drop(columns='Cabin')
test=test.drop(columns='Cabin')이렇게 하면 'Cabin' 열을 지울 수가 있다!
3.3. 성별
sns.countplot(data=train, x='Sex', hue='Survived')
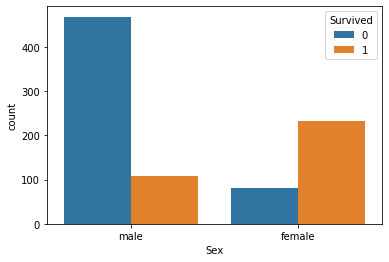
그래프를 띄우는 코드를 설명해보자면, train 데이터를 사용하고, x 축에는 '성별', 그리고 'Survived' 항목으로 구분해서 나누어본다. 라는 뜻이다.
결과를보면, 남자인 경우는 사망자수가 생존자수보다 더 많고, 여자인 경우는 사망자수보다 생존자 수가 더 많아, 생존률이 더 높은것을 확인할 수 있다. 이 성별에 해당하는 데이터는 머신러닝에게 유용한 정보를 제공할 수 있을 것이다.
train.loc[train['Sex']=='male', 'Sex']=0
train.loc[train['Sex']=='female','Sex']=1
test.loc[test['Sex']=='male','Sex']=0
test.loc[test['Sex']=='female','Sex']=1train 데이터와 test 데이터에 성별 데이터를 '인코딩' 해 준다. 머신러닝 알고리즘은 기본적으로 문자를 인식하지 못한다. 'male' 이라고 써있으면, 사람이야 바로 아 남성~ 하지만 머신러닝 알고리즘이 이걸 어떻게 알아듣겠는가? 그래서 이런 데이터를 0, 1 같은 숫자로 바꿔주는 일을 '인코딩' 이라고 한다.
첫 줄의 코드를 말로 설명하자면, "train 에서 [ train 데이터의 [성별] 이 'male' 인 사람의, '성별' 칸에는] = 0 이라고 입력해라." 정도로 해석할 수 있다. 밑에 줄들도 마찬가지.
이제 다음 칸에 "train['Sex']" 라고 쳐보면, 남성은 0, 여성은 1 로 데이터가 바뀌어있는것을 볼 수 있다.
3.4. Pclass (객실 등급)
sns.countplot(data=train, x='Pclass', hue='Survived')

보면, 1등석일수록 생존 확률이 높고, 3등석에는 사망률이 높아진다는 것을 알 수 있다. 역시 돈이 최고다. 아무튼 3등석보다 2등석이, 2등석보다 1등석이 생존 확률이 더 높다는 것은 머신러닝에게 좋은 정보로 작용할 것이다. 그럼 이 정보도 역시 인코딩 해주어야한다. 어? 근데 데이터가 1, 2, 3 숫자네? 아싸 개꿀~ 하려고 하는데 근데 여기서 문제가 생긴다.
기존 0과 1에서는 생기지 않았던 문제인데, 생각해보면 (1등석) + (2등석) = (3등석) 이 성립하는가?
(2등석) ^ 2 = (1등석) + (3등석) 이것도 성립하나? 개념상으로는 맞지 않다는것을 바로 알 수 있다. 이런 형태의 데이터를 '범주형 변수', 영어로 'categorical feature' 이라고 한다. 이렇게 숫자로 넣어주면 머신러닝 알고리즘은 딱 오해하기 좋다. 혹시나 수학 계산 과정이 필요한 알고리즘이라면, 위와 같은 오해를 하기 정말 좋은 상황이다. 이럴때 필요한게 바로 '원-핫 인코딩(one-hot encoding)' 이다.
이런 상황에서 원래대로 인코딩을 한다면, 데이터는 1개의 열에 모두 저장되어서 다음과 같이 표시될 것이다.
객실등급 : 1, 3, 2, 3, ....
하지만 원-핫 인코딩은 여러 개의 열을 추가한다. 이런 데이터에서 예를 들어보면,
객실 1등급 여부 : True, False, False, False, ...
객실 2등급 여부 : False, False, True, False, ...
객실 3등급 여부 : False, True, False, True, ...
이런식으로 인코딩을 진행한다. 이렇게 되면, 이 열들을 어떻게 더하고 곱하고 지지고 볶아도 중복이 나오지 않는다! 하지만 이 원핫 인코딩의 치명적인 단점은, 처리해야할 변수의 갯수가 아주아주 많아진다는 것이다. (그럴 일은 없겠지만) 만약에 객실이 60개 등급으로 이루어졌다면.... 총 60개의 변수가 생긴다. 이는 Tree 기반의 머신러닝 알고리즘에서 그닥 좋은 영향은 주지 못한다. 때에 따라서 원핫 인코딩할 변수가 너무 많다면, 그냥 1, 2, 3, ... 으로 인코딩 하기도 한다. (머신러닝 라이브러리 sklearn 에서는 이를 'LabelEncoder' 로 구현해두었다.) 상황에 따라 적절한 대처가 필요하다.
train['Pclass_3']=(train['Pclass']==3)
train['Pclass_2']=(train['Pclass']==2)
train['Pclass_1']=(train['Pclass']==1)
test['Pclass_3']=(test['Pclass']==3)
test['Pclass_2']=(test['Pclass']==2)
test['Pclass_1']=(test['Pclass']==1)코드를 말로 해석해보자면 "train 데이터에 있는 ['Pclass_3'] 이라는 열에 (없으면 만들고) train 데이터의 ['Pclass'] 열의 값이 3인 애들은 True, 아니면 False 로 입력해줘라" 라는 뜻이다. 밑에 줄도 마찬가지로 해석할 수 있다. 이렇게 되면 위에서 언급한 대로 원-핫 인코딩을 할 수 있다. 원-핫 인코딩을 완료했으니, 더이상 필요가 없어진 원래의 'Pclass' 열은 삭제하도록 하자.
train=train.drop(columns='Pclass')
test=test.drop(columns='Pclass')
3.5. 나이 (Age) 와 요금 (Fare)
그런 생각이 들었었다. 아무래도 나이가 어리면 비싼 요금은 내기 힘들 것이다. 그리고 비싼 요금은 높은 객실 등급과 더 연관이 클 것이다. 그렇다면 이것도 객실 등급처럼 생존 확률에 유의미한 영향을 끼쳤는지 한번 확인해보자.
sns.lmplot(data=train, x='Age', y='Fare', fit_reg=False, hue='Survived')

못보던게 하나가 등장했는데 'fit_reg' 이다. 이 lmplot(엘 엠 플랏) 은 이런 점찍혀있는 그래프와, 점들을 대표하는 하나의 직선이 있는 그래프인데, 나는 점만 보고 싶어서 선을 없앴다. 이 선을 없애는 명령이 'fit_reg=False' 이다. 선 궁금하면 한번 'fit_reg=True' 라고 해봐도 된다.여기서만 볼때는 딱히 유의미하다고 판단하기가 어렵다. 그래프를 확대해보자.
LowFare=train[train['Fare']<80]
sns.lmplot(data=LowFare, x='Age', y='Fare', hue='Survived')
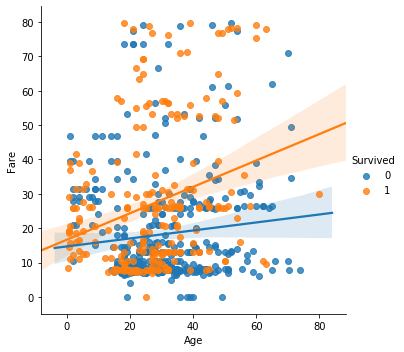
train 데이터에서 요금을 80불 이하로 지불한 사람들을 모아서 LowFare 이라는 변수로 저장한 후, 이 LowFare만을 활용해서 그래프를 다시 띄워본다.
이렇게 보니까 더더욱 알 수가 없다. 선을 보니 사망자와 생존자 간에 약간의 차이는 있지만, 점들의 위치를 봤을때는 유의미한 차이가 있다고 보기는 어려울 것 같다.
위에서 결측치를 찾아볼 때, test 데이터에 'Fare' 에서 한개의 결측치를 발견했었다. 그걸 그냥 0으로 채워버려야겠다.
test.loc[test['Fare'].isnull(),'Fare']=0요금은 뭔가 Pclass 와 연관이 있을 것 같기도 하지만, 나이 항목은 좀처럼 무언가를 발견할 수 없었다. 따라서 'Age' 변수만 지우기로 결정했다.
train=train.drop(columns='Age')
test=test.drop(columns='Age')
3.6. SibSp & Parch
영문도 모를 영어가 등장했다. 이 둘을 설명하자면,
SibSp : Sibling(형제자매) + Spouse(배우자)
Parch : Parents(부모) + Children(자녀)
두 단어들을 줄여놓은 것이다...낚였누 이 데이터들은 '같이 동행하는 일행' 에 대한 정보를 담고 있다고 할 수 있다.
이 둘을 더하고 + 1 (자기 자신) 을 한다면, '타이타닉에 탄 일행의 명수' 를 알수 있지 않을까? 아무래도 일행이 너무 많으면 다 찾아다니고 챙기고 하다가 탈출할 골든 타임을 놓쳤을 수도 있을 것이다.
train['FamilySize']=train['SibSp']+train['Parch']+1
test['FamilySize']=test['SibSp']+test['Parch']+1
figure, (ax1, ax2, ax3) = plt.subplots(nrows=1, ncols=3)
figure.set_size_inches(18,6)
sns.countplot(data=train, x='SibSp', hue='Survived', ax=ax1)
sns.countplot(data=train, x='Parch', hue='Survived', ax=ax2)
sns.countplot(data=train, x='FamilySize',hue='Survived', ax=ax3)

train, test 각 데이터의 SibSp, Parch 를 더하고 1을 더해서 'FamilySize' 라는 이름의 변수를 추가로 만들었다. 여기서 보면 알 수 있는 사실은, FamilySize 가 2 ~ 4 인 경우에는 생존률이 더 높았다는 사실을 알 수 있다. 핵가족의 전형적인 인원수이다. 이들은 빠르게 뭉쳐서 다같이 빠른 판단을 해서 생존률이 높은 것일까? 가설의 진실은 알 수 없지만, 이들 데이터가 가진 사실은 알 수 있다. 이들은 생존률이 높았다는 것이다.
과연 다른 가족 규모에서는 어떤지 보자.
train['Single']=train['FamilySize']==1
train['Nuclear']=(2<=train['FamilySize']) & (train['FamilySize']<=4)
train['Big']=train['FamilySize']>=5
test['Single']=test['FamilySize']==1
test['Nuclear']=(2<=test['FamilySize']) & (test['FamilySize']<=4)
test['Big']=test['FamilySize']>=5
figure, (ax1, ax2, ax3) = plt.subplots(nrows=1, ncols=3)
figure.set_size_inches(18,6)
sns.countplot(data=train, x='Single', hue='Survived', ax=ax1)
sns.countplot(data=train, x='Nuclear', hue='Survived', ax=ax2)
sns.countplot(data=train, x='Big',hue='Survived', ax=ax3)
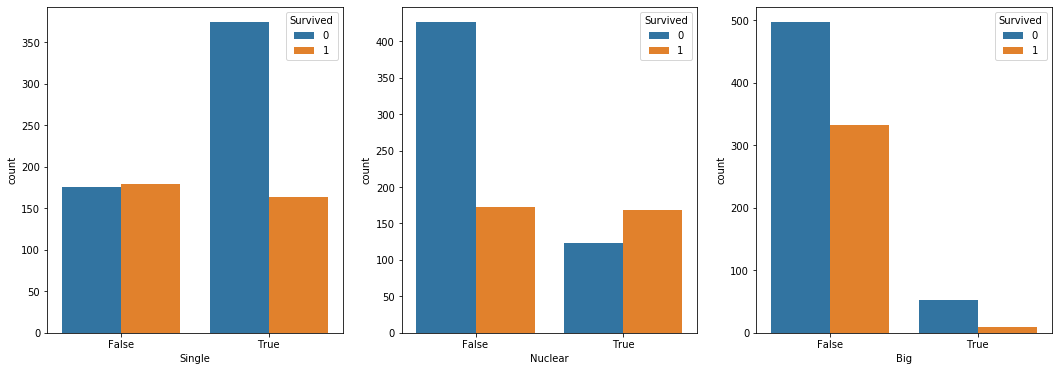
False 보다는 True 를 유심히 봐야하는 데이터다. 왜냐하면 가족 유형은 저 셋중 하나로 무조건 들어가게 되어있으니까.
코드를 설명하자면, train 과 test 데이터에서 FamilySize 가 1이면 'Single'로, 2~4 명이면 'Nuclear' 로, 그 이상이면 'Big' 으로 판단하고 각각 새로운 변수로 데이터에 추가했다.
확실히 다른 가족 형태보다 핵가족인 경우에만 생존률이 높았다는 사실을 확인할 수 있었다.
여기서 지금까지 원래 데이터셋에 Single, Nuclear, FamilySize, Big 등등을 만들어서 넣었는데, 이와 관련한 데이터들중에서 Nuclear 만 남기고 모두 지우려고 한다.
train=train.drop(columns=['Single','Big','SibSp','Parch','FamilySize'])
test=test.drop(columns=['Single','Big','SibSp','Parch','FamilySize'])
3.7. 선착장 (Embarked)
선착장에 따라서 생존률이 차이가 날까? 의구심이 들지만, 그래도 데이터를 보고 확인해야한다. 차이가 난다면 난다, 안난다면 안난다. 한번 그래프를 띄워보자.
sns.countplot(data=train, x='Embarked', hue='Survived')

얼라리? 차이가 있기는 하지만, 그 상황을 겪어보지 않아서 정확한 이유는 잘 모르겠다. 아무튼 우리가 내릴 수 있는 결론은 'C' 선착장에서 탄 승객들이 생존률이 높았다는 것이다. 이 Embarked 항목도, 머신러닝에게 좋은 정보가 될 것이다.
train['EmbarkedC']=train['Embarked']=='C'
train['EmbarkedS']=train['Embarked']=='S'
train['EmbarkedQ']=train['Embarked']=='Q'
test['EmbarkedC']=test['Embarked']=='C'
test['EmbarkedS']=test['Embarked']=='S'
test['EmbarkedQ']=test['Embarked']=='Q'
train=train.drop(columns='Embarked')
test=test.drop(columns='Embarked')위에서 했던 것처럼 원-핫 인코딩을 하고, 원래 데이터를 지워준다.
3.8. 이름 (Name)
영어 이름에는 성별 정보가 포함되어 있다. 이는 이름을 가지고도 생존 여부를 어느정도 예측할 수 있다고 볼 수도 있다. 또한 한 가족은 한 성씨(Last Name)를 따르니까, 위에서 말한 FamilySize를 남겨놓고 (LastName + FamilySize) 를 만들어서 일종의 FamilyID 를 만들 수도 있을 것이다. 예를들면, Johnson5 이런식이다. Johnson 성을 가진 5명 일행. 아마 일행중 한명이 사망했다면, 다른 구성원들도 사망했을지도 모른다. 이런식의 가설 세우기도 충분히 가능하지만, 난 귀찮으니 안하겠다. 해보고싶으면 한번 해봐도 좋을 것이다. 절대 내가 귀찮아서 그런게 아니다.
train['Name']=train['Name'].str.split(', ').str[1].str.split('. ').str[0]
test['Name']=test['Name'].str.split(', ').str[1].str.split('. ').str[0]train, test 의 'Name' 에다 그들의 Mr., Mrs., 등의 호칭을 가져와서 저장한다. 이름을 자세히 보면,
'이름', Mr. '성씨' 형태로 상당히 깔끔하게 정리되어있다. 위 코드는, 이 이름 데이터를 문자열로 받아서, 콤마와 온점 기준으로 가운데 있는 문자열을 가져오는 코드이다.
sns.countplot(data=train, x='Name', hue='Survived')
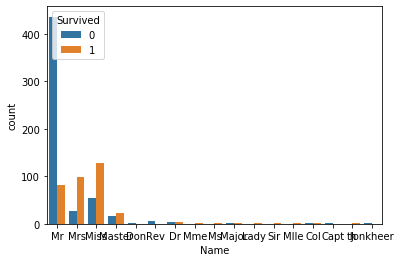
Mr 은 남자의 호칭이다. Ms, Mrs 는 여자의 호칭이다. 이는 위에서 보았던 성별 차이에 따른 생존률의 차이와 일맥상통한다. 하지만 여기서 특이한점은 'Master' 호칭의 사람들도 생존 숫자가 더 많았다는 것이다. 나중에 알게 되었는데, 이 'Master' 가 옛날 영어에서 어린 남자들을 지칭하는 호칭이란다. 카더라. 아무튼 우리가 알 수 있는 정보는, Master 호칭을 가진 남자들은 생존률이 더 높다는 것을 의미한다.
train['Master']=(train['Name']=='Master')
test['Master']=(test['Name']=='Master')
train=train.drop(columns='Name')
test=test.drop(columns='Name')
train=train.drop(columns='Ticket')
test=test.drop(columns='Ticket')train과 test 에서 'Master' 여부 True or False 를 구분하는 변수를 만들고, 나머지 이름 데이터를 삭제한다.
여기서 굳이 Ms, Mrs 를 따로 같이 뽑아주지 않았냐고 물어보신다면, 이미 얘네들은 여자이기 때문에, 머신러닝 알고리즘은 얘네들을 살 가능성이 높다고 판단할 것이라고 생각했다. 하지만 이 머신러닝은 남자들은 대부분 죽었다고 판단할 것이다. 우리가 데이터 분석을 하면서 정확도를 올릴 수 있는 방법은, 머신러닝이 죽었다고 판단할 남자들 중 살았을 확률이 높은 부분, 살았다고 판단했을 여자들이 죽었을 확률이 높은 부분을 찾아서 변수로 추가해주어야 정확도를 높일 수 있다. 여기서 Ms, Mrs 를 추가한다는것은 아무 의미 없이 변수만 늘리는 행위일 뿐이다. 위에서도 언급했듯이, 변수가 많아지면 결과에 좋은 영향을 끼치지 않을 가능성이 꽤 높다.
티켓은 티켓 번호를 의미한다. 그냥지우자. 귀찮다.
4. 머신러닝 모델 생성 및 학습
이제 머신러닝 모델을 만들고 학습시키고 데이터를 예측시키면 모든 과정이 끝이 난다.
머신러닝 모델은 sklearn(scikit-learn) 의 DecisionTree를 사용할 것이다.
from sklearn.tree import DecisionTreeClassifier그럼 이제 데이터를 머신러닝 알고리즘에 넣어줄 준비를 해야한다.
Ytrain=train['Survived']
feature_names=list(test)
Xtrain=train[feature_names]
Xtest=test[feature_names]
print(Xtrain.shape, Ytrain.shape, Xtest.shape)
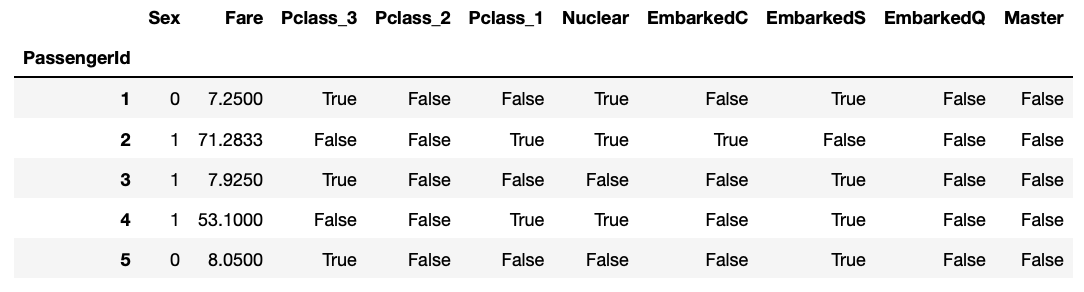
Xtrain.head()우리가 맞춰야 할 '생존여부' 를 Ytrain 이라는 이름에 변수에 저장했고, 승객 정보를 담고있는 나머지 데이터 (train 데이터에서 Survived 를 제외한 나머지 열) 들을 Xtrain, Xtest 라는 변수에 담았다.
다시 말하지만, 이 Xtrain 안에 있는 승객 정보를 가지고 Ytrain (생존여부) 를 학습한다. 그리고 머신러닝이 본 적 없는 데이터인 Xtest 에 대해서도 Ypred(예상 생존여부) 를 예측하는 것이 우리의 목표이다.
저 print 문이 실행된다면 아마 이렇게 출력될 것이다 :
(891, 10) (891,) (418, 10)
이때 확인해야 할 것은, Xtrain 과 Ytrain의 행 수가 일치하는지, Xtrain 과 Xtest 의 열 수가 일치하는지를 확인해야 한다. 이게 안맞으면 안돌아간다. 위에 데이터 분석 과정에서 무언가 빼먹었다는 뜻이다. '.head()' 라는 메소드는 해당 데이터프레임 (여기서는 Xtrain) 의 첫 5개 줄(행) 을 보여준다.
model=DecisionTreeClassifier(max_depth=8, random_state=18)
# random_state is an arbitrary number.
model.fit(Xtrain, Ytrain)
predictions=model.predict(Xtest)
submission['Survived']=predictions
submission.to_csv('Result.csv')
submission.head()model 은 머신러닝 모델인 DecisionTreeClassifier을 저장했다. 여기서는 깊이 8을 설정했다.
model.fit(Xtrain, Ytrain) : Xtrain 으로 Ytrain 을 학습해라.
model.predict(Xtest) : .fit() 이 끝난 이후에 실행할 수 있다. Xtest를 예측해라.
그러면 이제 submission 파일의 'Survived' 에다가 예측한 결과를 넣어서 '.to_csv' 로 저장할 수 있다. 저장된 파일은 주피터 노트북 파일과 같은 경로에 저장된다.
이걸 이제 캐글에 제출하면 나와 같은 결과를 얻을 것이다.

그짓말 안하고 타이타닉만 200번은 제출했다. 타이타닉 이제 그만하고싶다.
